
1. 概述
1.1. AI是什么
人工智能(Artificial Intelligence),英文缩写为AI。 是新一轮科技革命和产业变革的重要驱动力量,是研究、开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。
人工智能是智能学科重要的组成部分,它企图了解智能的实质,并生产出一种新的能与人类智能相似的方式做出反应的智能机器。人工智能是十分广泛的科学,包括机器人、语言识别、图像识别、自然语言处理、专家系统、机器学习,计算机视觉等。
20世纪70年代以来,人工智能被称为世界三大尖端技术之一(空间技术、能源技术、人工智能)。也被认为是21世纪三大尖端技术(基因工程、纳米科学、人工智能)之一。
1.2. AI大模型划分
根据其应用场景和功能进行分类:
自然语言处理(NLP)大模型:这类模型主要用于处理自然语言文本,如文本分类、命名实体识别、情感分析等。著名的自然语言处理大模型有GPT-3、BERT等。
计算机视觉(CV)大模型:这类模型主要用于处理图像和视频,如目标检测、语义分割、图像生成等。著名的计算机视觉大模型有Inception、ResNet、DenseNet等。
语音识别(ASR)大模型:这类模型主要用于语音信号的处理,如语音识别、语音合成等。著名的语音识别大模型有WaveNet、Transformer等。
推荐系统大模型:这类模型主要用于个性化推荐,如商品推荐、内容推荐等。著名的推荐系统大模型有 collaborative filtering、content-based filtering等。
强化学习(RL)大模型:这类模型主要用于解决决策问题,如游戏、机器人等。著名的强化学习大模型有 Q-learning、Deep Q-Network(DQN)等。
按照部署方式划分:
云侧大模型:部署在云端,其拥有更大的参数规模、更多的算力资源以及海量的数据存储需求等特点。
端侧大模型:通常部署在手机、PC 等终端上,具有参数规模小、本地化运行、隐私保护强等特点。
按照训练类型划分:
机器学习模型:是一种基于数据和经验进行学习的模型,它们可以通过对大量数据进行训练和分析,自主地学习数据中的规律和模式。常见的机器学习模型包括决策树、支持向量机、神经网络等。
深度学习模型:深度学习模型是一种基于神经网络的机器学习模型,它们可以通过多层神经元网络进行训练和学习,实现对复杂数据的处理和分析。常见的深度学习模型包括卷积神经网络、循环神经网络、变换器等。
规则模型:是一种基于人类经验和知识进行推理的模型,它们通过对人类经验和知识进行归纳和整理,建立一套规则和逻辑来进行推理和决策。常见的规则模型包括专家系统、决策树等。
弱人工智能模型:是一种专注于单一任务处理的模型,它们可以通过模拟人类某一领域的智能行为来进行推理和决策。常见的弱人工智能模型包括语音识别、图像识别、自然语言处理等。
强人工智能模型:是一种可以胜任多种任务处理的模型,它们具备自我学习和自我适应的能力,可以根据环境的变化来进行动态调整和决策。
LLM:大语言模型(Large Language Model)是指使用大量文本数据训练的深度学习模型,可以生成自然语言文本或理解语言文本的含义。是NLP领域中的一种特定类型的语言模型,通常是基于深度学习技术的大规模预训练模型。它是基于机器学习和自然语言处理技术构建的,可以理解和生成自然语言文本,可以进行文本分类、情感分析、命名实体识别、机器翻译、问答系统、对话系统、文本摘要、信息提取、语音识别等NLP任务。总的来说,LLM是一种特殊的NLP技术,是NLP领域的进一步发展。
1.3. 开源大模型
1.4. 生态工具
Ollama:一个功能强大的本地大语言模型LLM运行专家。是为了降低本地大语言模型(LLM)的部署难度。
Hugging Face: 为自然语言处理 (NLP) 模型训练和部署平台
Unsloth:大语言模型微调框架。简化了语言模型的微调流程,并提供了一种直接有效的方法来提升模型性能
检索增强生成(RAG):通过引用外部知识库的信息来生成答案或内容,具有较强的可解释性和定制能力
向量数据库(Vector DataBase):是专门用来存储和查询向量的数据库,可以处理更多非结构化数据(比如图像和音频)。在机器学习和深度学习中,数据通常以向量形式表示。
MaxKB/AnythingLLM:本地知识库技术方案。降低我们建立私有知识库人工智能问答系统的难度
Open WebUI:是一个可扩展、功能丰富、用户友好的自托管Web界面,支持离线运行和多种LLM(大型语言模型)运行器。
LangChain:是一个帮助在应用程序中使用大型语言模型(LLM)的编程框架。主要支持python、typescript。
Spring AI:是一个面向 AI 工程的java应用框架。
2. 本地大模型部署
Ollama 是一个强大的工具,设计用于在 Docker 容器中部署 LLM。Ollama 的主要功能是在 Docker 容器内部署和管理 LLM,它使该过程变得非常简单。它帮助用户快速在本地运行大模型,通过简单的安装指令,可以让用户执行一条命令就在本地运行开源大型语言模型,例如 Llama 3。
Ollama 将模型权重、配置和数据捆绑到一个包中,定义成 Modelfile。它优化了设置和配置细节,包括 GPU 使用情况。
2.1. 安装Ollama
前提需要安装docker
Linux用户 Docker 提供了便利安装的脚本,可以按照以下方式安装:
curl -fsSL https://get.docker.com -o get-docker.sh sudo DOWNLOAD_URL=https://mirrors.ustc.edu.cn/docker-ce sh get-docker.shWindows用户在docker官网下载docker desktop即可。
Ollama安装
linux一键安装:
curl https://ollama.ai/install.sh | shwindows可以下载安装包,双击安装。安装包下载地址:https://ollama.com/download/OllamaSetup.exe
ollama运行成功之后,默认端口号是11434
2.2. 运行大模型
至少需要 8 GB 的 RAM 来运行 7B 模型,16 GB 来运行 13B 模型,以及 32 GB 来运行 33B 模型
2.3. 安装Open WebUI
下载 open-webui框架
GitHub:https://github.com/open-webui/open-webui(官方文档)
在cmd/powershell中,利用docker下载
docker run -d -p 8080:8080 -v open-webui:/app/backend/data --name open-webui --restart always ghcr.io/open-webui/open-webui:main
如果出现以下错误:
docker: Error response from daemon: failed to create task for container: failed to create shim task: OCI runtime create failed: runc create failed: systemd not running on this host, cannot use systemd cgroups manager: unknown.打开/etc/docker/daemon.json,添加或修改以下内容:
"exec-opts": ["native.cgroupdriver=cgroupfs"]运行成功之后的效果如下:
访问:localhost:8080
第一次需要先注册再登录,就可以使用了!登录进去之后
选择一个模型之后就可以聊天啦
点击登录用户名 --> 管理员面板 --> 设置 --> 模型 --> 就可以拉取新模型、删除模型或者创建模型
点击登录用户名 --> 设置 --> 个性化 --> 点击开启,并点击管理按钮 --> 添加记忆 --> 输入自己的定制化内容,最后别忘记保存
再次进行聊天,就可以实现知识库的效果啦!
2.4. Ollama REST API
Ollama提供了原生 API 让开发者可以通过编程的方式与模型进行交互。具体文档:https://github.com/ollama/ollama/blob/main/docs/api.md
2.4.1 /api/generate
这个接口用于根据输入的提示文本生成响应,这有一次对话。
请求参数
model:要使用的模型名称,例如llama2。prompt:输入的提示文本。stream:可选参数,布尔值,默认为true,表示是否以流式方式返回结果。
curl 示例
curl http://localhost:11434/api/generate \
-d '{
"model": "llama2",
"prompt": "介绍一下故宫",
"stream": false
}'2.4.2 /api/chat
在 Ollama 里进行对话式交互(会话)时,你可以通过不断地向 /api/generate 接口发送提示信息来模拟会话过程。在 Ollama 中专门用于实现对话式交互的接口/api/chat,它相较于不断拼接提示信息使用 /api/generate 接口更为便捷和高效,能够自动处理对话上下文。
第一次请求
curl http://localhost:11434/api/chat \
-d '{
"model": "llama2",
"messages": [
{
"role": "user",
"content": "你好"
}
],
"stream": false
}'第二次请求
curl http://localhost:11434/api/chat \
-d '{
"model": "llama2",
"messages": [
{
"role": "user",
"content": "你好"
},
{
"role": "assistant",
"content": "你好!有什么我可以帮忙的吗?"
},
{
"role": "user",
"content": "故宫在哪里"
}
],
"stream": false
}'消息顺序:
messages数组中的消息顺序很重要,要按照对话的先后顺序依次排列。
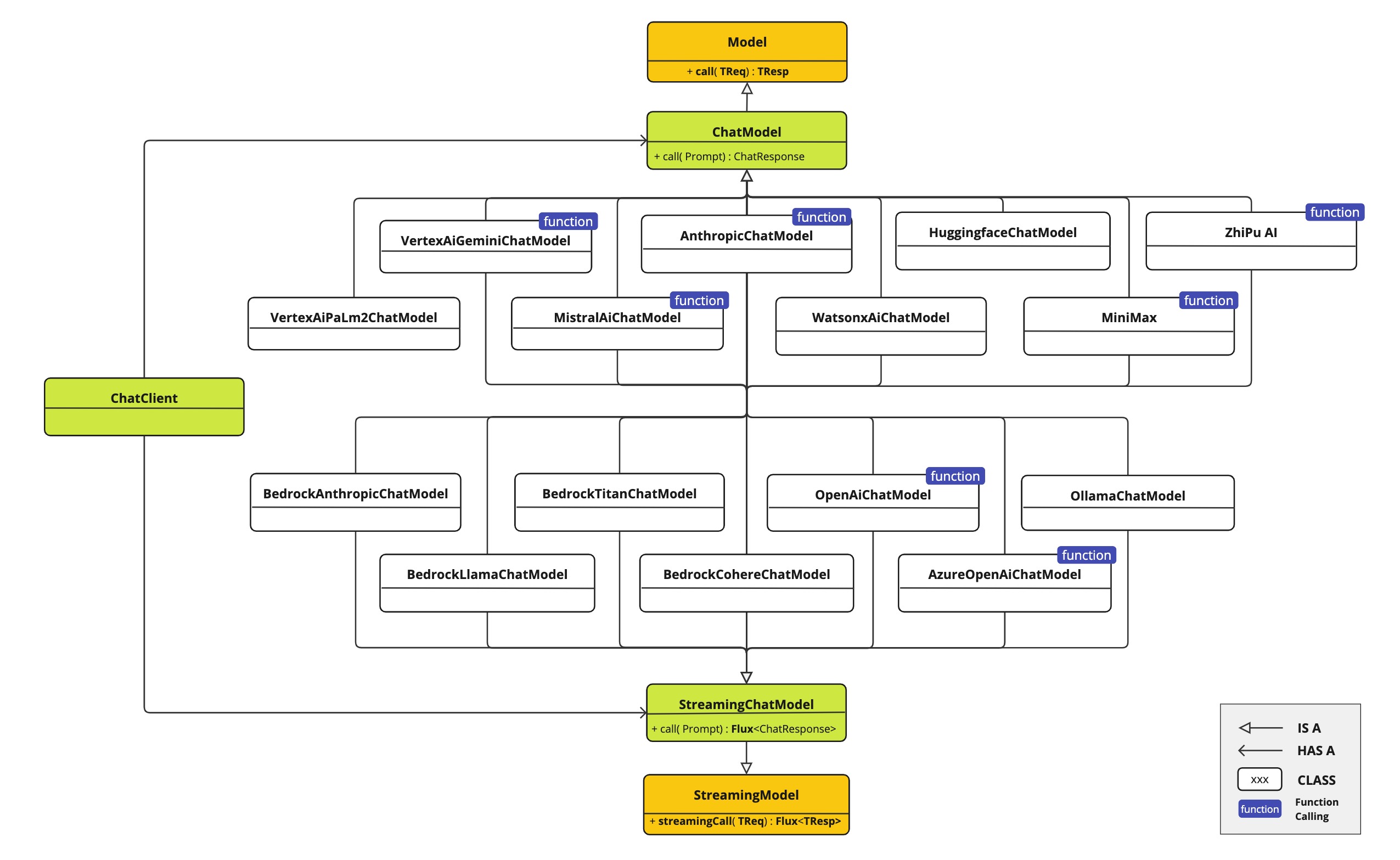
3. Spring AI
Spring AI 是一个面向 AI 工程的应用框架,其目标是将 Spring 生态系统的可移植性和模块化设计等设计原则应用到 AI 领域,并推动将 POJO 作为应用的构建块应用于 AI 领域。
3.1. 概念
Model:人工智能模型是用来处理和生成信息的算法,通常模仿人类的认知功能。有许多不同类型的人工智能模型,每种模型都适合特定的场景。Spring AI目前支持将输入和输出处理为语言、图像和音频的模型。
Prompts:提示是指导人工智能模型产生特定输出的基于语言的输入。对于熟悉ChatGPT的人来说,提示可能看起来只是在发送到API的对话框中输入的文本。然而,它包含的远不止这些。提示(Prompt)不仅仅是单个字符串,而是一系列消息。当每条消息仍然是文本形式时,都被分配了一个特定的角色。这些角色对消息进行分类,澄清人工智能模型提示的每个片段的上下文和目的。这种结构化的方法增强了与人工智能沟通的细微差别和有效性,因为提示的每个部分在互动中都扮演着独特而明确的角色。
RAG(Retrieval Augmented Generation):检索增强生成。涉及一个批处理风格的编程模型,在该模型中,程序从文档中读取非结构化数据,对其进行转换,然后将其写入矢量数据库。从高层来看,这是一个ETL(提取、转换和加载)管道。矢量数据库用于RAG技术的检索部分。
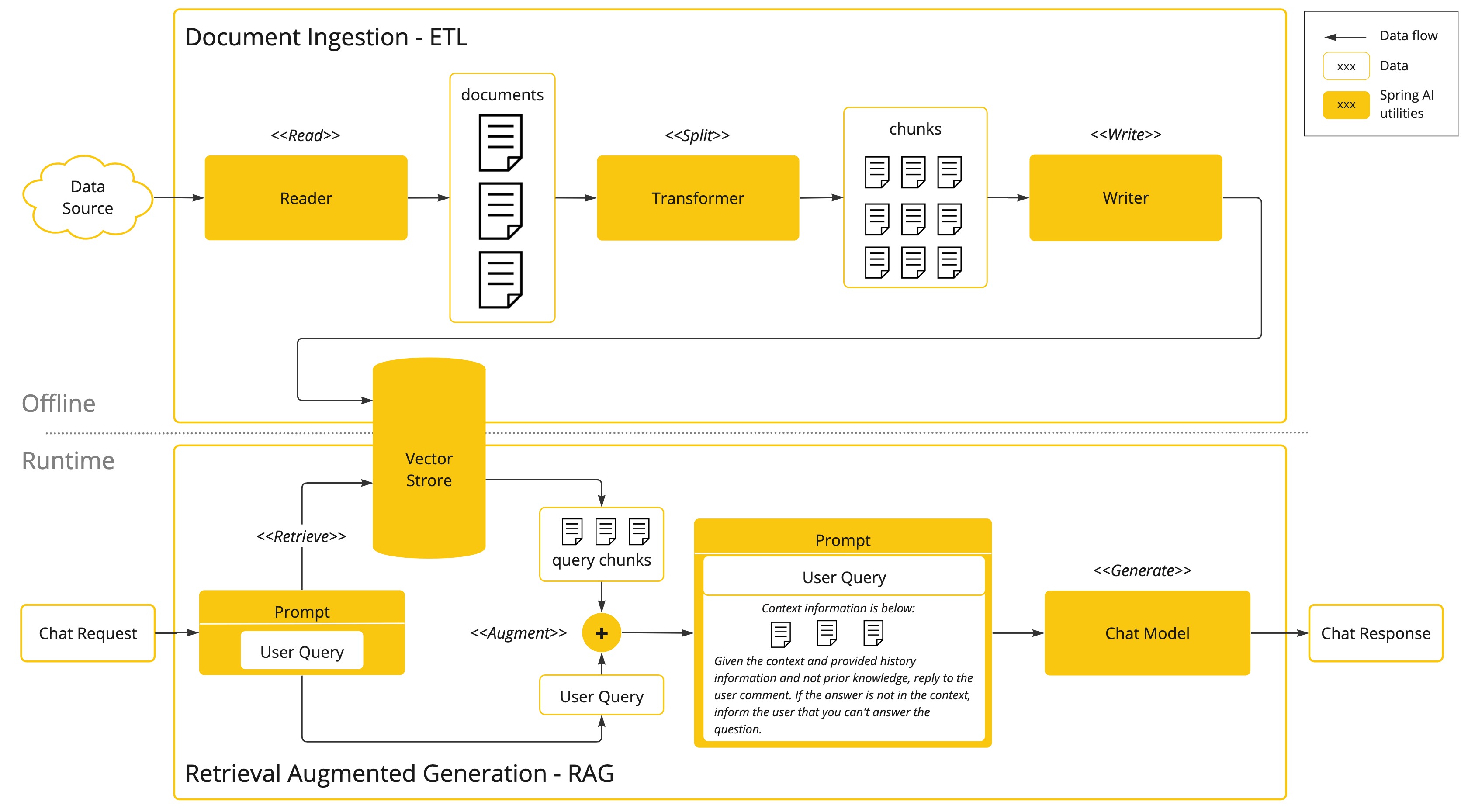
Embeddings:嵌入将文本转换为数字数组或矢量,使人工智能模型能够处理和解释语言数据。这种从文本到数字的转换是人工智能如何与人类语言互动和理解人类语言的关键因素。作为一名探索人工智能的Java开发人员,没有必要理解这些矢量表示背后复杂的数学理论或具体实现。基本了解它们在人工智能系统中的作用和功能就足够了
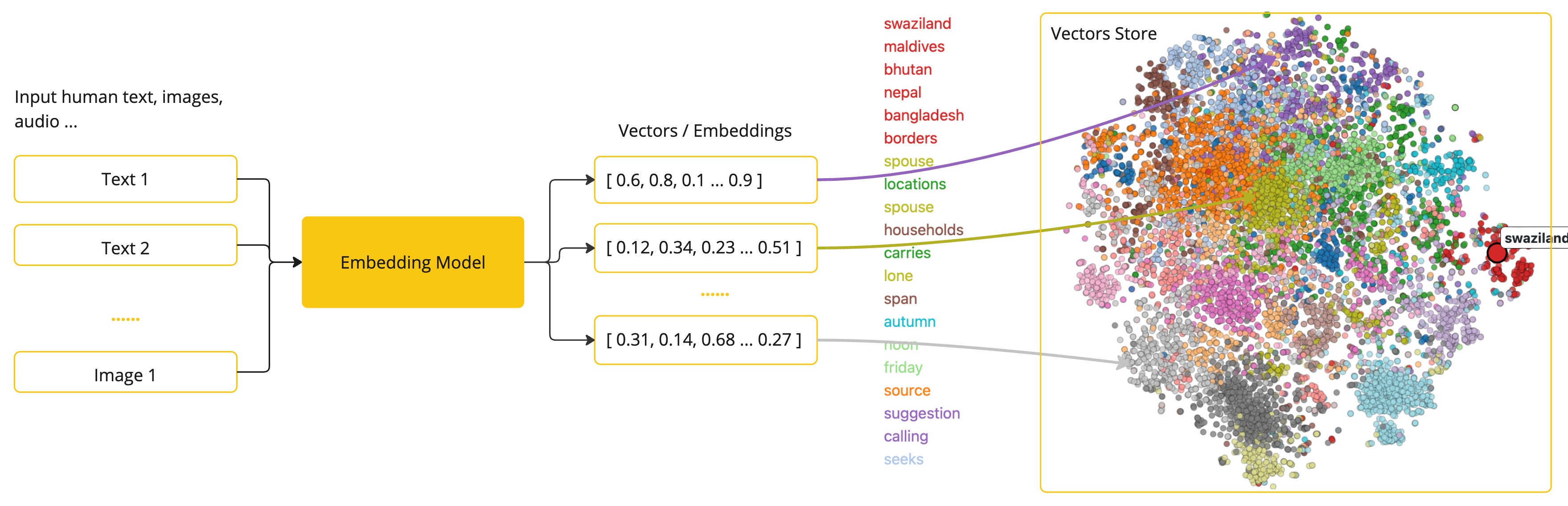
3.2. API架构
支持来自 OpenAI、Microsoft、Amazon、Google、Amazon Bedrock、Huggingface 等的 AI 模型。
3.3. 快速入门(ChatClient)
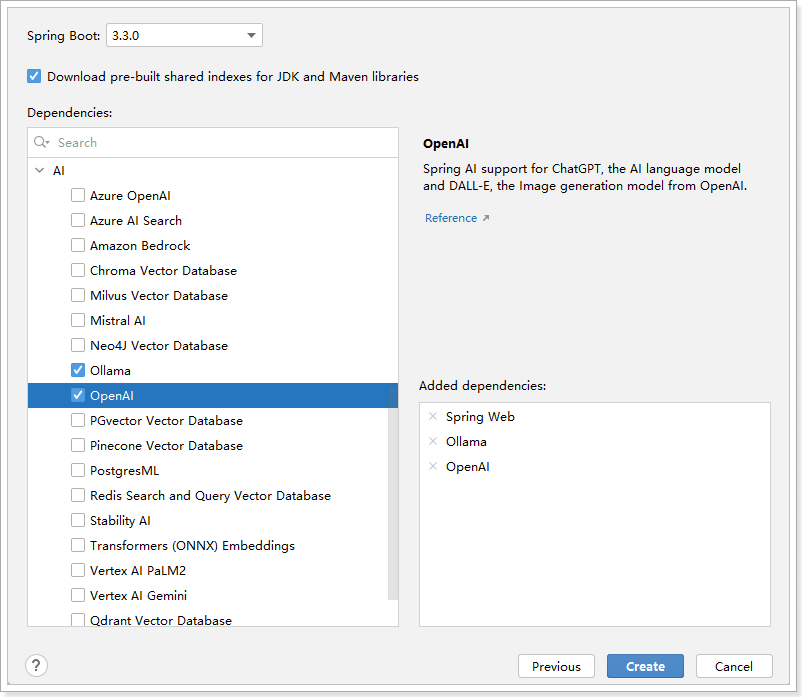
ChatClient提供了一个fluent API,用于与人工智能模型进行通信。它支持同步和流式编程模型。fluent API具有用于构建作为输入传递给AI模型的Prompt的组成部分的方法。Prompt包含指导AI模型输出和行为的教学文本。从API的角度来看,提示由一组消息组成。
Spring AI 提供了 Spring Boot 的自动配置,为您创建一个原型 ChatClient.Builder bean,供您注入到您的类中。这里是一个简单的示例,演示如何获取对简单用户请求的字符串响应。
@RestController
@RequestMapping("chat")
public class ChatClientController {
private ChatClient chatClient;
// public ChatClientController(ChatClient.Builder chatClientBuilder) {
// this.chatClient = chatClientBuilder.build();
// }
/**
* 1.快速入门
* @param userInput
* @return
*/
@GetMapping
public String generation(String userInput) {
return this.chatClient.prompt()
.user(userInput)
.call()
.content();
}
/**
* 2.返回ChatResponse
* @param userInput
* @return
*/
@GetMapping("response")
public String testResp(String userInput){
ChatResponse chatResponse = chatClient.prompt()
.user(userInput)
.call()
.chatResponse();
return chatResponse.getResult().getOutput().getContent();
}
/**
* 3.返回流式Response
* @param userInput
* @return
*/
@GetMapping(value = "stream", produces = "text/plain;charset=UTF-8")
public Flux<String> testStream(String userInput){
Flux<String> output = chatClient.prompt()
.user(userInput)
.stream()
.content();
return output;
}
/**
* 4.defaultSystem
* @param openAiChatModel
*/
public ChatClientController(OpenAiChatModel openAiChatModel) {
this.chatClient = ChatClient
.builder(openAiChatModel)
.defaultSystem("李先锋老师,是尚硅谷最帅的实力派java老师!").build();
}
}3.4. ChatModel
Chat Model API为开发人员提供了将人工智能聊天完成功能集成到应用程序中的能力。它利用预训练的语言模型,如GPT(生成预训练转换器),以自然语言对用户输入生成类似人类的响应。
Spring AI Chat Model API 设计为一个简单便携的界面,用于与各种人工智能模型交互,使开发人员能够在不同的模型之间切换,只需最少的代码更改。这种设计符合Spring的模块化和互换性理念。
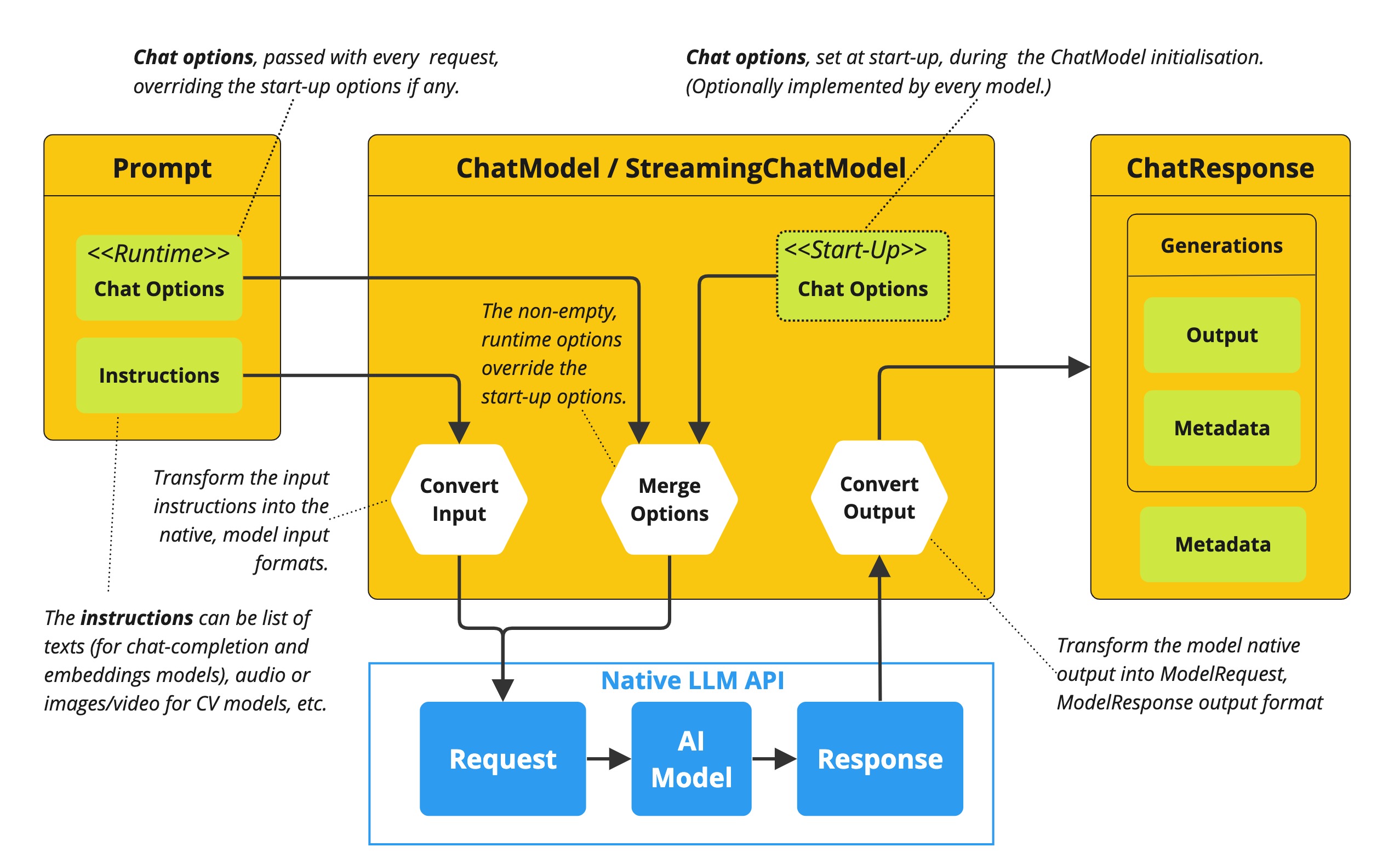
OpenAiChatModel
添加依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-openai-spring-boot-starter</artifactId>
</dependency>添加配置:
# openai chat config
spring.ai.openai.base-url=https://api.xty.app
spring.ai.openai.api-key=sk-xxxxxxxxxxxxxxx
spring.ai.openai.chat.options.model=gpt-3.5-turbo具体代码:
@RestController
@RequestMapping("openai")
public class OpenAiController {
@Autowired
private OpenAiChatModel openAiChatModel;
/**
* 文本聊天
* @param prompt
* @return
*/
@GetMapping("chat")
public String chat(String prompt) {
String result = this.openAiChatModel.call(prompt);
return result;
}
/**
* 文本聊天(流式输出)
* @param prompt
* @return
*/
@GetMapping(value = "stream", produces = "text/plain;charset=UTF-8")
public Flux<String> chatStream(String prompt) {
Flux<String> resp = this.openAiChatModel.stream(prompt);
return resp;
}
/**
* 自定义运行参数
* @param prompt
* @return
*/
@GetMapping("chat2")
public String chat2(String prompt) {
ChatResponse res = this.openAiChatModel.call(new Prompt(prompt, OpenAiChatOptions.builder()
.withModel("gpt-3.5-turbo")
.build()));
String result = res.getResult().getOutput().getContent();
return result;
}
}OllamaChatModel
添加依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-ollama-spring-boot-starter</artifactId>
</dependency>添加配置:
# ollama config
spring.ai.ollama.base-url=http://localhost:11434
# spring.ai.ollama.chat.model=llama3:latest
spring.ai.ollama.chat.model=qwen2:7b具体代码:
@RestController
@RequestMapping("ollama")
public class OllamaController {
@Autowired
private OllamaChatModel ollamaChatModel;
/**
* 文本问答
* @param prompt
* @return
*/
@RequestMapping("chat")
public String chat(String prompt) {
String result = this.ollamaChatModel.call(prompt);
return result;
}
/**
* 文本问答(流式)
* @param prompt
* @return
*/
@RequestMapping(value = "stream", produces = "text/plain;charset=UTF-8")
public Flux<String> stream(String prompt) {
Flux<String> result = this.ollamaChatModel.stream(prompt);
return result;
}
}3.5. 高级语法
文字转图片
/**
* 图像生成
* @param prompt
* @return
*/
@GetMapping("image")
public String image(String prompt) {
ImageResponse response = this.openAiImageModel.call(new ImagePrompt(prompt));
Image image = response.getResult().getOutput();
// String b64Json = response.getResult().getOutput().getB64Json();
return "<img src='" + image.getUrl() + "'>";
}文字转音频
/**
* 文本转音频
* @param prompt
* @return
*/
@GetMapping("textToAudio")
public String textToAudio(String prompt) {
SpeechResponse response = this.openAiAudioSpeechModel.call(new SpeechPrompt(prompt));
byte[] binaryData = response.getResult().getOutput();
this.saveAudioToFile(binaryData, "output.mp3");
return "处理成功";
}
private void saveAudioToFile(byte[] audioBinaryData, String outputPath) {
try (FileOutputStream fos = new FileOutputStream(outputPath)) {
fos.write(audioBinaryData);
System.out.println("音频文件已成功保存至: " + outputPath);
} catch (IOException e) {
e.printStackTrace();
System.err.println("保存音频文件时发生错误.");
}
}消息及角色(Message & Role)
每条消息(Message)都被分配了一个特定的角色。这些角色对消息进行分类,阐明AI模型提示的每个部分的上下文和目的。这种结构化的方法增强了与人工智能沟通的细微差别和有效性,因为提示的每个部分在互动中都扮演着独特而明确的角色。
主要角色包括:
System Role:指导人工智能的行为和响应风格,设置人工智能如何解释和回复输入的参数或规则。这类似于在开始对话之前向人工智能提供指令。
User Role:代表用户的输入——他们对人工智能的问题、命令或陈述。这个角色是基本的,因为它构成了人工智能反应的基础。
Assistant Role:AI对用户输入的响应。这不仅仅是一个答案或反应,对于保持对话的流畅性至关重要。通过跟踪人工智能之前的响应(其“Assistant Role”消息),该系统确保了连贯和上下文相关的交互。助手消息也可能包含功能工具调用请求信息。它就像人工智能中的一个特殊功能,在需要时用于执行特定功能,如计算、获取数据或其他不仅仅是说话的任务。
Tool/Function Role:该角色处理会话中的特定任务或操作。当系统角色设定人工智能的整体行为时,功能角色专注于执行用户要求的某些动作或命令。这就像人工智能中的一个特殊功能,在需要执行特定功能时使用,如计算、获取数据或其他任务,而不仅仅是说话。这一角色使人工智能能够在对话回应之外提供实际帮助。
/**
* 用户角色
* @param text
* @return
*/
@RequestMapping(value = "role", produces = "text/plain;charset=UTF-8")
public Flux<String> role(String text) {
Flux<String> result = this.ollamaChatModel.stream(
new UserMessage(text)
// new SystemMessage("李先锋,尚硅谷java讲师,以其帅气的外表,强大的实力,幽默的风格,深受学员的喜爱!")
// new AssistantMessage("""
// xxxxxx
// """)
);
return result;
}多模态(Multimodality)
在 Spring AI 中,多模态(Multimodal)通常指的是集成和处理多种类型的输入数据(如文本、图像、音频、视频等)来进行建模和推理的能力。这种技术能够使模型从不同的模态(即不同形式的数据)中获取信息,从而增强模型的表现力和决策能力
这些学习的基础原则是由现代教育之父约翰·阿莫斯·孔美尼斯在他的著作《感官世界图解》中阐述的,该书的创作可以追溯到 1658 年。

模态:指的是数据的不同形式或类别。例如,图像、文本、语音、视频、传感器数据等都是不同的模态。每种模态都提供了独特的信息,比如图像包含视觉信息,文本传达语义信息,音频捕捉声音和语调等。
多模态数据:是指在一个任务中同时使用多种类型的数据输入。
多模态大语言模型(LLM)功能使模型能够结合图像、音频或视频等其他模态处理和生成文本。
媒体字段目前仅适用于用户输入消息(例如UserMessage)。它对系统消息没有意义。包含LLM响应的AssistantMessage仅提供文本内容。要生成非文本媒体输出,您应该使用专用的单模态模型之一。
/**
* 多模态
* @return
*/
@GetMapping("multiModel")
public String multiModel(String text) throws IOException {
ClassPathResource resource = new ClassPathResource("/static/multimodal.test.png");
var userMessage = new UserMessage(
text, // content
List.of(new Media(MimeTypeUtils.IMAGE_PNG, resource))); // media
ChatResponse response = this.openAiChatModel.call(new Prompt(List.of(userMessage)));
return response.getResult().getOutput().getContent();
}效果如下:

函数调用(Function Calling)
Function Calling 是现代 AI 模型,尤其是在大语言模型(如 GPT-4)中引入的一种强大功能。它允许 AI 模型不仅生成自然语言,还能够根据输入的语境自动调用预定义的函数,以执行特定的任务或操作。这种能力大大扩展了 AI 系统的应用范围,使其能够与外部系统进行交互、执行动态任务,并在不同的上下文中提供更具针对性和智能化的响应。
在 Spring AI 框架中,Function Calling 作为一种增强 AI 模型功能的方法,使模型能够直接调用外部服务、函数或 API,执行任务或获取特定数据。这一功能不仅提高了模型的实用性,也为开发者提供了更高的灵活性,能够将模型应用到更广泛的实际场景中。
例如:
当用户在对话中询问“当前的天气如何?”时,模型可以自动调用一个天气查询函数,并返回实时的天气信息。
用户询问订单状态时,模型可以调用订单查询函数,直接提供订单的最新状态,而不仅仅是给出一个模板化的回答。

具体过程如下:
一个聊天请求和函数定义信息一起发送给AI模型。后者包括函数名称、描述(例如解释模型何时应调用函数)及输入参数。
当模型决定调用函数时,它将使用输入参数调用函数,并将输出返回给模型。
Spring AI为您处理此对话。它将函数调用分派给相应的函数,并将结果返回给模型。
模型可以执行多个函数调用来检索它需要的所有信息。
一旦获取了所需的所有信息,模型将生成响应。
定义一个天气服务类:
// 定义一个service统一处理天气请求
public class MockWeatherService implements Function<MockWeatherService.Request, MockWeatherService.Response> {
public record Request(String location) {}
public record Response(double temp, String location) {}
// 接收gpt提取的location信息,并返回weather信息
// apply 方法是 Function 接口中定义的抽象方法。它接收一个 Request 对象作为输入,并返回一个 Response 对象作为输出。
// 通过这个方法,模拟天气服务处理输入的请求,生成相应的天气数据并返回
public Response apply(Request request) {
// 假装调用了第三方的天气服务器接口
if ("北京".equals(request.location)){
return new Response(30.0, request.location);
} else if ("上海".equals(request.location)){
return new Response(28.0, request.location);
} else {
return new Response(0.0, "未知城市");
}
}
}初始化到Spring容器:
@Configuration
public class Config {
@Bean
// @Description 注释是可选的,但是一个重要的属性,提供一个功能描述,帮助模型理解何时调用该函数。
@Description("获取某个城市的天气信息") // function description
public Function<MockWeatherService.Request, MockWeatherService.Response> weatherFunction() {
return new MockWeatherService();
}
}使用演示:
/**
* 函数调用
* @param text
* @return
*/
@GetMapping("function")
public String function(String text){
Prompt prompt = new Prompt(text, OpenAiChatOptions.builder()
.withFunction("weatherFunction").build()
);
ChatResponse response = this.openAiChatModel.call(prompt);
return response.getResult().getOutput().getContent();
}效果:

检索增强生成(RAG)
全称:Retrieval Augmented Generation
如何为人工智能模型配备未经训练的信息?有三种技术可用于定制人工智能模型以整合您的数据:
微调:这种传统的机器学习技术包括剪裁模型并改变其内部权重。然而,对于机器学习专家来说,这是一个具有挑战性的过程,对于像GPT这样的模型来说,由于其规模,这是极其耗费资源的过程。此外,某些型号可能不提供此选项。
提示填充:一个更实用的替代方案是将数据嵌入到提供给模型的提示中。给定模型的令牌限制,需要使用技术在模型的上下文窗口中显示相关数据。这种方法通俗地称为“填充提示”。Spring AI库帮助您实现基于“填充提示(filling the prompt)”技术的解决方案,也称为检索增强生成(RAG)。
函数调用:这项技术允许注册将大型语言模型连接到外部系统API的自定义用户函数。Spring AI大大简化了支持函数调用所需编写的代码。
4. 向量数据库(Vector Databases)
向量数据库是RAG目前最主要的手段。
矢量数据库用于将您的数据与 AI 模型集成。 使用它们的第一步是将数据加载到向量数据库中。 然后,当要将用户查询发送到 AI 模型时,首先检索一组相似的文档。 然后,这些文档将作为用户问题的上下文,并与用户的查询一起发送到 AI 模型。 这种技术称为检索增强生成(RAG,Retrieval Augmented Generation)。
4.1. 概论
什么是向量数据库
在向量数据库中,查询不同于传统的关系数据库。 它们执行的不是完全匹配,而是相似性搜索。 当将向量作为查询时,向量数据库将返回与查询向量“相似”的向量。
向量是对象或数据点(point)的数学表示,向量的每个元素对于对象的某个特征或者属性。例如,在图像识别系统中,向量可以表示为一个图像,向量的每个元素代表像素值或该像素特征/描述符。在音乐推荐系统中,每个向量代表一首歌曲,向量的每个元素代表歌曲的每个特征,比如节奏、流派、歌词等。
向量数据库针对高维向量的高效存储和查询进行了优化,通常使用了专门的数据结构和索引技术。
向量数据库与AI的关系
向量数据库与AI的关系非常密切,它是AI技术发展的重要基石之一。向量数据库在AI领域的应用主要体现在以下几个方面:
数据表示与处理:在机器学习和深度学习中,数据通常以向量的形式表示。例如,图像可以表示为像素值的向量,文本可以表示为词向量或句子向量。向量数据库能够高效地存储和处理这些向量数据,为AI模型提供优化的存储和查询能力。
自然语言处理:在NLP中,词嵌入技术(如Word2Vec、GloVe和BERT)将词语转换为多维向量,有助于捕捉词语之间的语义关系。这些向量表示可应用于文本分类、情感分析、机器翻译等任务。向量数据库能够存储和处理这些嵌入向量,支持高效的相似度搜索和检索功能。
大型语言模型:大型语言模型等AI模型的创新应用基础建立在所谓的“向量嵌入”技术之上。这些模型生成的向量嵌入包含大量的属性或特征,需要专门的数据库来管理和查询。向量数据库为此提供了优化的存储和查询能力,满足了AI模型对数据处理的需求。
垂直领域服务:在构建基于大语言模型的行业智能应用中,向量数据库结合大模型和自有知识资产,能够构建垂直领域的智能服务。通过向量嵌入,将企业知识库文档和数据转化为向量表示,并与大模型进行交互,实现专有、私域的垂直行业智能化应用。
非关系型数据库:向量数据库属于非关系型数据库的一种,它们不依赖于传统的表结构来存储数据,而是采用各种数据模型,如键值对、列族、文档和图形。这使得非关系型数据库在处理大量分散的数据、并行运算和高度变化的数据结构方面具有优势。
综上所述,向量数据库通过优化存储和查询能力,支持高效的数据处理和模型训练,是AI技术发展中不可或缺的一部分。
向量数据库有哪些
Chroma DB是一个开源的、AI本地的嵌入式向量数据库,旨在简化通过使知识、事实和技能对大型语言模型(LLM)规模上的机器学习模型可插拔,从而创建由自然语言处理驱动的LLM应用程序的过程,同时避免幻觉。
可以直接部署在云上,也可以在现场运行,使其成为任何企业的可行选择
Pipecone 是一个托管的、云原生的向量数据库,具有简单的API和无需基础架构的优势。
但是:需要付费(免费版只支持单容器部署),不支持本地部署
Milvus:是一款云原生的开源向量数据库,专为向量相似性搜索和 AI 应用赋能。采用存储与计算分离的架构设计,所有组件均为无状态组件,极大地增强了系统弹性和灵活性。Milvus起步较早,拥有最高的GitHub星级评级和强大的社区支持。
主要基于公有云提供SaaS服务,免费版(适用于新手用户开发单一项目)、标准版(适用于少于5人的小团队)和企业版(适用于规模以上的企业)
Weaviate 是一个低延迟的云原生向量数据库,它支持多种媒体类型(如文本、图片等),并且具有语义搜索、问题答案提取、分类等功能,还支持可定制的模型(例如 PyTorch/TensorFlow/Keras)。
但是:付费
Qdrant是一个开源向量数据库,专为下一代AI应用程序设计。它是面向云原生的,并提供RESTful和gRPC API以管理嵌入。Qdrant的特性强大,支持图像、语音和视频搜索,以及与AI引擎的集成。
其他:Deep Lake、redisearch、MongoDB Atlas、Pgvector、Elasticsearch Relevance Engine(ESRE)、Cassandra等

4.2. Qdrant向量数据库
Qdrant 的正确读法:quadrant
为什么是Qdrant
搭建向量存储解决方案的成本高昂,并且还需要考虑扩展性的问题。
简单易用:仅需几分钟便可轻松搭建大型向量相似性搜索服务。Qdrant 数据库提供了一个用户友好的 API 及 客户端。
多客户端支持:同时提供多种语言的 SDK,包括java、Go、python等。
高效相似搜索:Qdrant 一个专门设计用于向量相似度搜索而设计。它在处理大量数据时非常快速且准确。
灵活性:可以存储和搜索不同类型的数据,如图像、文本、音频等。
可伸缩性 — Qdrant 能够有效处理大量向量,因此具有可伸缩性。
Qdrant 是一个强大的工具,可以帮助企业解锁语义嵌入的力量,彻底改变文本搜索。它提供了一个可靠和可扩展的解决方案,用于管理高维数据,具有出色的查询性能和易于集成。
应用场景:语义文本搜索、相似图像搜索、推荐系统、聊天机器人和匹配引擎等。
安装Qdrant
在线安装:需要科学上网
docker run -d --name qdrant -p 6333:6333 -p 6334:6334 -v D:\\Resource\\docker\\storage\\qdrant:/qdrant/storage:z qdrant/qdrant
docker run -d --name qdrant -p 6333:6333 -p 6334:6334 -v /opt/qdrant:/qdrant qdrant/qdrant设置z选项以指定多个容器可以共享绑定安装的内容
Qdrant 现在可以访问:
REST API:
本地主机ip:6333网页用户界面:
本地主机:6333/dashboardGRPC API:
本地主机ip:6334
4.3. Qdrant基本概念
Qdrant中的集合类似于MySQL数据库中的表,用于统一存储同一类向量数据,集合中存储的每一条数据,在Qdrant中称为点(points)。

Collection集合
是一组可以搜索的点的命名,同一集合中每个点的向量必须具有相同的维度,并通过单个度量进行比较。
距离度量(Distance)用于衡量向量之间的相似性,Qdrant支持以下最流行的指标类型:
余弦相似度(Cosine Similarity) - 余弦相似度是一种衡量两个事物相似程度的方式。可以将其视为一把标尺,用于测量两个点之间的距离,但与其测量距离不同,它测量的是两个事物之间的相似程度。它常用于文本中比较两个文档或句子之间的相似程度。余弦相似度的输出范围从0到1,其中0表示两个事物完全不相似,1表示两个事物完全相同。这是一种简单而有效的比较两个事物的方法!
点积(Dot Product) - 类似于余弦相似度。在处理数字时,它通常用于机器学习和数据科学中。点积相似度通过将两组数字中的值相乘,然后将这些乘积加起来来计算得到。越高的总和意味着两组数字越相似。它就像一个衡量两组数字彼此匹配程度的比例尺。
欧式距离(Euclidean Distance) - 欧式距离是一种测量空间中两点之间距离的方式,类似于我们在地图上测量两个地方之间距离的方式。它的计算方式是找到两点坐标之间差值的平方和的平方根。这种距离度量方式通常在机器学习中用于衡量两个数据点的相似性或差异性,换句话说,用于了解它们之间有多远。
曼哈顿距离(Manhattan Distance) - 也称为城市街区距离,是一种在几何空间中测量两点之间距离的度量方式。它表示两个点在标准坐标系上的绝对轴距总和。曼哈顿距离是标量空间中两点间各维度差的绝对值之和。曼哈顿距离在计算机科学、图像处理、数据挖掘等领域有着广泛的应用。例如,在推荐系统中,曼哈顿距离可以用于计算用户之间或物品之间的相似度;在图像处理中,可以用于衡量图像之间的相似性。
Points点
是Qdrant操作的核心实体。点是由向量和可选载荷组成的记录。它看起来像这样:
// This is a simple point
{
"id": 129,
"vector": [0.1, 0.2, 0.3, 0.4],
"payload": {"color": "red"},
}您可以根据向量相似性在一个集合中的点之间进行搜索。任何点修改操作都是异步的,分两步进行:在第一阶段,操作被写入预写日志。 在此之后,即使机器失去电源,服务也不会丢失数据。
Vectors向量
Vectors (or embeddings) 向量(或嵌入)
向量(或嵌入)是Qdrant向量搜索引擎的核心概念。向量定义了向量空间中对象之间的相似性,如果一对向量在向量空间中是相似的,这意味着它们所表示的对象在某些方面是相似的。
例如:如果您有一组图像,则可以将每个图像表示为向量。如果两个图像相似,它们的向量在向量空间中将彼此接近。
为了获得对象的矢量表示,需要使用矢量化算法。通常,该算法是一种将对象转换为固定大小向量的神经网络。
现代神经网络可以输出不同形状和大小的向量,Qdrant支持其中的大多数。让我们来看看Qdrant支持的最常见的向量类型。
密集矢量(Dense Vectors):这是最常见的向量类型。它是一个简单的数字列表,长度固定,列表中的每个元素都是浮点数。
// A piece of a real-world dense vector [ -0.013052909, 0.020387933, -0.007869, -0.11111383, -0.030188112, -0.0053388323, .... ]稀疏向量(Sparse Vectors):密集向量的值就是一个普通的Double数组 而稀疏向量由两个并列的 数组 indices 和 values 组成。
向量:(1.0, 0.0, 1.0, 3.0)
密集格式:[1.0, 0.0, 1.0, 3.0]
稀疏格式:(4, [0, 2, 3], [1.0, 1.0, 3.0])
4表示向量的长度(元素个数)
[0, 2, 3]就是indices数组
[1.0, 1.0, 3.0]是values数组
表示向量0的位置的值是1.0,2的位置的值是1.0,而3的位置的值是3.0,其他的位置都是0
// A sparse vector with 4 non-zero elements { "indexes": [1, 3, 5, 7], "values": [0.1, 0.2, 0.3, 0.4] }多向量(Multivectors):Qdrant支持在单个点中存储多个密集向量。您可以上传一个密集向量矩阵,而不是单个密集向量。
// A multivector of size 4 "vector": [ [-0.013, 0.020, -0.007, -0.111], [-0.030, -0.055, 0.001, 0.072], [-0.041, 0.014, -0.032, -0.062], .... ]矩阵的长度是固定的,但矩阵中每个点的向量数量可以不同。
命名向量(Named Vectors):在Qdrant中,您可以在同一数据点中存储多个不同大小的向量。当您需要使用多个嵌入来定义数据以表示不同的特征或模态(例如图像、文本或视频)时,这很有用。
每个矢量都应该有一个唯一的名称。矢量可以表示不同的模态,您可以使用不同的嵌入模型来生成它们。
Payload负载
Qdrant的一个重要特征是能够将附加信息与向量一起存储,这些信息在Qdrant术语中称为有效载荷。Qdrant允许您存储任何可以使用JSON表示的信息。以下是一个典型的有效载荷示例:
{
"name": "jacket",
"colors": ["red", "blue"],
"count": 10,
"price": 11.99,
"locations": [
{
"lon": 52.5200,
"lat": 13.4050
}
],
"reviews": [
{
"user": "alice",
"score": 4
},
{
"user": "bob",
"score": 5
}
]
}4.4. Http客户端
创建集合
PUT /collections/{collection_name}
{
"vectors": {
"size": 300,
"distance": "Cosine"
}
}参数说明:
collection_name 集合名字(必填)
vectors 参数定义
size:向量的长度(也叫维度)
distance:向量相似度算法,主要有“Cosine”、“Euclid”、"Dot"三种算法。
更新集合
Qdrant 1.4增加了在运行时更新更多集合参数的支持。HNSW索引、量化和磁盘配置现在可以更改,而无需重新创建集合。分段(带索引和量化数据)将在后台自动重建,以匹配更新的参数。要将没有命名向量的集合的向量数据放在磁盘上,请使用“”作为名称:
PATCH /collections/{collection_name}
{
"vectors": {
"": {
"on_disk": true
}
}
}获取集合信息
GET /collections/{collection_name}检查集合
GET http://localhost:6333/collections/{collection_name}/exists删除集合
DELETE http://localhost:6333/collections/{collection_name}新增点
PUT /collections/{collection_name}/points
{
"points": [
{
"id": "5c56c793-69f3-4fbf-87e6-c4bf54c28c26", // id支持数字
"payload": {"color": "red"},
"vector": [0.9, 0.1, 0.1]
}
]
}批量新增点
PUT /collections/{collection_name}/points
{
"batch": {
"ids": [1, 2, 3],
"payloads": [
{"color": "red"},
{"color": "green"},
{"color": "blue"}
],
"vectors": [
[0.9, 0.1, 0.1],
[0.1, 0.9, 0.1],
[0.1, 0.1, 0.9]
]
}
}或者:
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"payload": {"color": "red"},
"vector": [0.9, 0.1, 0.1]
},
{
"id": 2,
"payload": {"color": "green"},
"vector": [0.1, 0.9, 0.1]
},
{
"id": 3,
"payload": {"color": "blue"},
"vector": [0.1, 0.1, 0.9]
}
]
}删除点
根据id列表删除点:
POST /collections/{collection_name}/points/delete
{
"points": [0, 3, 100]
}根据过滤条件删除点:
POST /collections/{collection_name}/points/delete
{
"filter": {
"must": [
{
"key": "color",
"match": {
"value": "red"
}
}
]
}
}更新向量
更新向量对应的点必须存在。
PUT /collections/{collection_name}/points/vectors
{
"points": [
{
"id": 1,
"vector": {
"image": [0.1, 0.2, 0.3, 0.4]
}
},
{
"id": 2,
"vector": {
"text": [0.9, 0.8, 0.7, 0.6, 0.5, 0.4, 0.3, 0.2]
}
}
]
}更新负载
根据id更新负载
POST /collections/{collection_name}/points/payload
{
"payload": {
"property1": "string",
"property2": "string"
},
"points": [
0, 3, 100
]
}根据过滤条件更新负载
POST /collections/{collection_name}/points/payload
{
"payload": {
"property1": "string",
"property2": "string"
},
"filter": {
"must": [
{
"key": "color",
"match": {
"value": "red"
}
}
]
}
}负载索引
为了更有效地进行过滤搜索,Qdrant允许您通过指定字段的名称和类型来为负载字段创建索引。
在实践中,我们建议对那些可能对结果限制最大的字段创建索引。例如,为对象ID使用索引将比仅具有少数可能值的颜色索引更有效,因为每个记录都是唯一的。在涉及多个字段的复合查询中,Qdrant将尝试首先使用最具限制性的索引。
PUT /collections/{collection_name}/index
{
"field_name": "name_of_the_field_to_index",
"field_schema": "keyword"
}删除负载
根据id集合从点中删除指定负载keys
POST /collections/{collection_name}/points/payload/delete
{
"keys": ["color", "price"],
"points": [0, 3, 100]
}根据过滤条件从点中删除指定负载keys
POST /collections/{collection_name}/points/payload/delete
{
"keys": ["color", "price"],
"filter": {
"must": [
{
"key": "color",
"match": {
"value": "red"
}
}
]
}
}清除载荷:
POST /collections/{collection_name}/points/payload/clear
{
"points": [0, 3, 100]
}根据过滤条件清除,此处略。。。。
稀疏向量
Qdrant中的稀疏向量保存在特殊的存储器中,并在单独的索引中索引,因此它们的配置不同于密集向量。
创建集合并使用稀疏向量:
PUT /collections/{collection_name}
{
"sparse_vectors": {
"text": { },
}
}新增一个点并使用稀疏向量:
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"vector": {
"text": {
"indices": [1, 3, 5, 7],
"values": [0.1, 0.2, 0.3, 0.4]
}
}
}
]
}多向量
创建集合并使用多向量
PUT /collections/{collection_name}
{
"vectors": {
"image": {
"size": 4,
"distance": "Dot"
},
"text": {
"size": 8,
"distance": "Cosine"
}
}
}新增点:
PUT /collections/{collection_name}/points
{
"points": [
{
"id": 1,
"vector": {
"image": [0.9, 0.1, 0.1, 0.2],
"text": [0.4, 0.7, 0.1, 0.8, 0.1, 0.1, 0.9, 0.2]
}
},
{
"id": 2,
"vector": {
"image": [0.2, 0.1, 0.3, 0.9],
"text": [0.5, 0.2, 0.7, 0.4, 0.7, 0.2, 0.3, 0.9]
}
}
]
}4.5. java客户端
引入依赖:
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-qdrant-store-spring-boot-starter</artifactId>
</dependency>原生java客户端
@Test
void testQdrant() throws ExecutionException, InterruptedException {
QdrantClient client = new QdrantClient(
QdrantGrpcClient.newBuilder("127.0.0.1", 6334, false).build()
);
client.createCollectionAsync("test",
Collections.VectorParams.newBuilder()
.setDistance(Collections.Distance.Cosine)
.setSize(4).build()).get();
}4.6. SpringAI集成
矢量数据库用于将您的数据与AI模型集成。使用它们的第一步是将数据加载到向量数据库中。然后,当用户查询要发送到AI模型时,首先检索一组类似的文档。然后,这些文档作为用户问题的上下文,并与用户的查询一起发送到AI模型。这种技术被称为检索增强生成(RAG)。
Embeddings嵌入
要讲数据插入到向量数据库,需要使用嵌入模型将文本内容转换为数值数组或List<Double>,称为向量嵌入(vector embeddings)。例如可以使用Word2Vec, GLoVE,BERT或者 OpenAI的text-embedding-ada-002等嵌入模型,将单词、句子或段落转换为向量嵌入。
嵌入的工作原理是将文本、图像和视频转换为浮点数数组,称为向量。这些矢量旨在捕捉文本、图像和视频的含义。嵌入数组的长度称为向量的维数。通过计算两段文本的向量表示之间的数值距离,应用程序可以确定用于生成嵌入向量的对象之间的相似性。
您需要选择一个与所使用的高级人工智能模型匹配的嵌入模型。例如,对于OpenAI的ChatGPT,我们使用OpenAiEmbeddingModel和一个名为text-embedding-ada-002的模型。
EmbeddedModel接口的设计围绕两个主要目标:
可移植性:此接口可确保跨各种嵌入模型的轻松适应性。它允许开发人员以最小的代码更改在不同的嵌入技术或模型之间进行切换。这种设计符合Spring的模块化和互换性理念。
简单性:EmbeddedModel简化了将文本转换为嵌入的过程。通过提供像embed(字符串文本)和embed(文档文档)这样的简单方法,它降低了处理原始文本数据和嵌入算法的复杂性。这种设计选择使开发人员,特别是那些不熟悉人工智能的开发人员,更容易在他们的应用程序中利用嵌入,而无需深入研究底层机制。
快速入门
注意:建议提前创建具有适当
dimensions和配置的Qdrant Collection。如果未创建Collection,QdrantVectorStore将尝试使用Cosine similarity和EmbeddingModel中配置的dimensions创建一个Collection。
引入依赖:略。。。(java客户端)
配置说明:
spring.ai.vectorstore.qdrant.host=<host of your qdrant instance> spring.ai.vectorstore.qdrant.port=<the GRPC port of your qdrant instance> spring.ai.vectorstore.qdrant.api-key=<your api key> spring.ai.vectorstore.qdrant.collection-name=<The name of the collection to use in Qdrant>具体代码:
@SpringBootTest class AiDemoApplicationTests { @Autowired private VectorStore vectorStore; @Test void contextLoads() { List <Document> documents = List.of( new Document("Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!", Map.of("meta1", "meta1")), new Document("The World is Big and Salvation Lurks Around the Corner"), new Document("You walk forward facing the past and you turn back toward the future.", Map.of("meta2", "meta2"))); // Add the documents to Qdrant vectorStore.add(documents); // Retrieve documents similar to a query List<Document> results = vectorStore.similaritySearch(SearchRequest .query("Spring") .withSimilarityThreshold(0.75) .withTopK(3)); results.forEach(result -> System.out.println(result.getContent())); } }打印结果:
Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!! Spring AI rocks!!
高级特性
接口中的similaritySearch方法允许检索与给定查询字符串相似的文档。可以使用以下参数对这些方法进行微调:
k: 一个整数,指定要返回的类似文档的最大数量。这通常被称为“top K”搜索 或“K nearest neighbors”(KNN)。
threshold:一个从0到1的双精度值,其中接近1的值表示更高的相似性。默认情况下,例如,如果将阈值设置为0.75,则只返回相似度高于此值的文档。
Filter.Expression:一个用于传递流畅的DSL(领域特定语言)表达式的类,其功能类似于SQL中的“where”子句,但它仅适用于文档的元数据键值对。
filterExpression:一种基于ANTLR4的外部DSL,接受过滤表达式作为字符串。例如,对于country、year和isActive等元数据键,您可以使用以下表达式:
country == 'UK' && year >= 2020 && isActive == true。
您可以将 SQL-like filter expressions作为字符串传递给similaritySearch重载之一。
常规示例:
"country == 'BG'"
"genre == 'drama' && year >= 2020"
"genre in ['comedy', 'documentary', 'drama']"您可以使用以下运算符构建复杂的表达式:
EQUALS: '=='
MINUS : '-'
PLUS: '+'
GT: '>'
GE: '>='
LT: '<'
LE: '<='
NE: '!=
AND: 'AND' | 'and' | '&&';
OR: 'OR' | 'or' | '||';
IN: 'IN' | 'in';
NIN: 'NIN' | 'nin';
NOT: 'NOT' | 'not';代码格式:
FilterExpressionBuilder b = new FilterExpressionBuilder();
Expression exp = b.eq("country", "BG").build();
Expression exp = b.and(b.eq("genre", "drama"), b.gte("year", 2020)).build();5. MongoDB数据库
MongoDB 是在2007年由DoubleClick公司的几位核心成员开发出的一款分布式文档数据库,由C++语言编写。旨在为WEB应用提供可扩展的高性能数据存储解决方案。MongoDB是一个介于关系数据库和非关系数据库之间的产品,是非关系数据库当中功能最丰富,最像关系数据库的。
适用场景:
网站数据:Mongo非常适合实时的插入,更新与查询,并具备网站实时数据存储所需的复制及高度伸缩性。
高伸缩性的场景:Mongo非常适合由数十或数百台服务器组成的数据库。
大尺寸,低价值的数据:使用传统的关系型数据库存储一些数据时可能会比较昂贵,在此之前,很多时候程序员往往会选择传统的文件进行存储。
缓存:由于性能很高,Mongo也适合作为信息基础设施的缓存层。在系统重启之后,由Mongo搭建的持久化缓存层可以避免下层的数据源过载。
例如:弹幕、直播间互动信息、朋友圈信息、物流场景等
5.1. 相关概念
在MongoDB中数据主要的组织结构就是:数据库、集合和文档。
MongoDB中每一条数据记录就是一个文档,文档存储在集合当中,集合存储在数据库中。
相关概念如下:
5.2. 数据结构
MongoDB 中的记录就是一个 BSON (Binary JSON,是 JSON 文档的二进制表示)文档,它是由键值对组成的数据结构,类似于 JSON 对象,是 MongoDB 中的基本数据单元。字段的值可能包括其他文档、数组和文档数组。

MongoDB 集合存在于数据库中,没有固定的结构,也就是 无模式 的,这意味着可以往集合插入不同格式和类型的数据。不过,通常情况下插入集合中的数据都会有一定的关联性。

集合不需要事先创建,当第一个文档插入或者第一个索引创建时,如果该集合不存在,则会创建一个新的集合。
数据库用于存储所有集合,而集合又用于存储所有文档。一个 MongoDB 中可以创建多个数据库,每一个数据库都有自己的集合和权限。
5.3. 安装启动
创建目录:
mkdir -p /opt/mongo/data/db安装:
docker run -d --restart=always -p 27017:27017 --name mongodb -v /opt/mongo/data/db:/data/db mongo:7.0.0进入容器:
docker exec -it mongodb mongosh基本命令:
# 当前db版本
db.version()
# 查看当前db的链接机器地址
db.getMongo()
# 帮助
db.help()
# 退出命令行
quit() 5.4. 基本命令行
数据库操作
mongodb 中的库就类似于传统关系型数据库中库的概念,用来通过不同库隔离不同应用数据。
# 如果数据库不存在,则创建数据库,否则切换到指定数据库。
use tingshu
# 查看数据库列表
show dbs
# 删除当前数据库
db.dropDatabase()
有集合存在的数据库,才能查看到。
集合操作
在 MongoDB 中,创建集合不是必须操作。当你插入一些文档时,MongoDB 会自动创建集合。
db.myCollection.insertOne({"name": "hello mongodb"})效果如下:

集合的新增和删除:
# 新增集合
db.createCollection("myCollection2")
# 查看集合
show collections
# 删除集合
db.myCollection2.drop()演示效果如下:

文档操作
文档是一组键值(key-value)对。MongoDB 的文档不需要设置相同的字段,并且相同的字段不需要相同的数据类型,这与关系型数据库有很大的区别,也是 MongoDB 非常突出的特点。
需要注意的是:
MongoDB区分类型和大小写。
MongoDB的文档不能有重复的键。
新增:
db.collection.insertOne() 用于向集合插入一个新文档
db.collection.insertMany() 用于向集合插入一个或者多个文档查询:
db.collection.find()条件查询:
更新:
# 只更新匹配到的第一条记录
db.user.updateOne({'age': 20}, {$set: {'sex': false}})
# 更新匹配到的所有记录
db.user.updateMany({'age': 20}, {$set: {'sex': false}})删除:
# 根据id删除
db.user.remove(id)
# 删除所有
db.user.remove({})
# 根据条件删除
db.user.remove({name: 'liuyan'})效果如下:

5.5. 客户端工具
资料中提供了MongoDB UI客户端工具:mongodb-compass-1.40.2-win32-x64.msi
安装后配置链接地址:

5.6. SpringData MongoDB
官方介绍如下:

大概意思如下:
Spring Data for MongoDB是Spring Data项目的一部分,该项目旨在为新的数据存储提供一个熟悉且一致的基于Spring的编程模型,同时保留特有的存储的特性和功能。
Spring Data MongoDB项目提供了与MongoDB文档数据库的集成。Spring Data MongoDB的关键功能领域是一个以POJO为中心的模型,用于与MongoDB DBCollection交互,并轻松编写Repository风格的数据访问层。
搭建demo工程


application.properties配置内容如下:
spring.data.mongodb.host=172.16.116.100
spring.data.mongodb.port=27017
spring.data.mongodb.database=atguigu
# 或者
spring.data.mongodb.uri=mongodb://172.16.116.100:27017/atguigu编写实体类
@AllArgsConstructor
@NoArgsConstructor
@Data
@Document("user") // 指定实体类对应的collection
public class User {
@Id
private Long id;
private String name;
private Integer age;
private Boolean sex;
}增删改查
@SpringBootTest
class MongoDemoApplicationTests {
@Autowired
private MongoTemplate mongoTemplate;
@Test
void testInsert() {
// 新增一条
// this.mongoTemplate.insert(new User(1L, "柳岩", 20, false));
// 新增多条
this.mongoTemplate.insertAll(Arrays.asList(
new User(2L, "马蓉", 21, false),
new User(3L, "小鹿", 22, false),
new User(4L, "老王", 23, true),
new User(5L, "小亮", 24, true),
new User(6L, "小猪", 25, true)
));
}
@Test
void testFind(){
// 1.根据id查询
System.out.println(this.mongoTemplate.findById(1L, User.class));
System.out.println("==============================================");
// 2.查询所有
this.mongoTemplate.findAll(User.class).forEach(System.out::println);
System.out.println("==============================================");
// 3.根据条件查询一个
System.out.println(this.mongoTemplate.findOne(Query.query(Criteria.where("name").is("柳岩")), User.class));
System.out.println("==============================================");
// 4.根据条件查询多个
this.mongoTemplate.find(
Query.query(
Criteria.where("sex").is(true).and("age").gte(23))
// 根据年龄降序排列
.with(Sort.by(Sort.Order.desc("age")))
// 分页查询:页码从0开始
.with(Pageable.ofSize(2).withPage(1)),
User.class).forEach(System.out::println);
System.out.println("==============================================");
// 5.模糊查询
this.mongoTemplate.find(Query.query(Criteria.where("name").regex("小")), User.class)
.forEach(System.out::println);
}
@Test
void testUpdate(){
// 更新一个
UpdateResult updateResult = this.mongoTemplate.updateFirst(
Query.query(Criteria.where("sex").is(false)),
Update.update("name", "凤姐").set("age", 32),
User.class);
System.out.println("更新数量:" + updateResult.getModifiedCount());
// 更新多个
UpdateResult result = this.mongoTemplate.updateMulti(
Query.query(Criteria.where("sex").is(false)),
Update.update("age", 32),
User.class);
System.out.println("更新数量:" + result.getModifiedCount());
}
@Test
void testDelete(){
DeleteResult result = this.mongoTemplate.remove(Query.query(Criteria.where("_id").is(1)), User.class);
System.out.println("删除文档数量:" + result.getDeletedCount());
}
}6. 实战-小谷同学
6.1. 成品展示
6.2. 环境搭建
解压课前资料中的xiaogu.zip包,导入到idea开发工具
guli-admin:

guli-chat:

guli-ai

6.3. 策略模式
策略模式介绍
定义: 策略模式定义了一系列算法,并将每个算法封装起来,使他们可以相互替换,且算法的变化不会影响到使用算法的客户。
主要解决:在有多种算法相似的情况下,使用 if...else 所带来的复杂和难以维护。它把采取哪一种算法或采取哪一种行为的逻辑与算法或行为的逻辑混合在一起,统统列在一个多重条件语句里面,比使用继承的办法还要原始和落后。

入门程序
抽象策略
public interface ILog {
void print(String msg);
}具体策略
public class ConsoleLog implements ILog {
@Override
public void print(String msg) {
System.out.println("打印到console控制台:" + msg);
}
}
public class FileLog implements ILog {
@Override
public void print(String msg) {
System.out.println("打印到日志文件:" + msg);
}
}策略客户端
public class LogClient {
private ILog log;
public LogClient(ILog log) {
this.log = log;
}
public void save(String msg){
this.log.print(msg);
}
}测试类:
public class LogClientTest {
public static void main(String[] args) {
LogClient logClient1 = new LogClient(new ConsoleLog());
logClient1.save("hello console...");
LogClient logClient2 = new LogClient(new FileLog());
logClient2.save("hello file...");
}
}SpringBoot整合
public interface ILog {
void print(String msg);
}
@LogValidator(LogType.FILE_TYPE)
public class FileLog implements ILog{
@Override
public void print(String msg) {
System.out.println("输出到文件:" + msg);
}
}
@LogValidator(LogType.CONSOLE_TYPE)
public class ConsoleLog implements ILog{
@Override
public void print(String msg) {
System.out.println("输出到控制台:" + msg);
}
}
public enum LogType {
FILE_TYPE(1, "文件日志"),
CONSOLE_TYPE(2, "控制台日志"),
;
public int type;
public String name;
LogType(int type, String name) {
this.type = type;
this.name = name;
}
}
@Target(ElementType.TYPE)
@Retention(RetentionPolicy.RUNTIME)
@Documented
@Component
@Inherited
public @interface LogValidator {
LogType value() default LogType.CONSOLE_TYPE;
}
@Component
public class LogClient implements ApplicationContextAware {
private ConcurrentHashMap<Integer, ILog> logMap = new ConcurrentHashMap<>();
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
String[] logBeanNames = applicationContext.getBeanNamesForAnnotation(LogValidator.class);
if (logBeanNames == null || logBeanNames.length == 0){
return;
}
for (String logBeanName : logBeanNames) {
// 获取spring容器中的ILog类型的对象
ILog log = applicationContext.getBean(logBeanName, ILog.class);
// 获取ILog对象上的LogValidator注解对象
LogValidator logValidator = log.getClass().getAnnotation(LogValidator.class);
// 根据注解中LogType的值,放入map中
logMap.put(logValidator.value().type, log);
}
}
public void log(Integer type, String msg){
logMap.get(type).print(msg);
}
}
@SpringBootTest
public class StrategyTest {
@Autowired
private LogClient logClient;
@Test
public void test(){
logClient.log(1, "hello strategy....");
}
}6.4. 项目管理
ChatProjectController:
/**
* 项目配置Controller
*
* @author lixianfeng
* @date 2024-06-27
*/
@RestController
@Tag(name = "项目后台管理", description = "该智能聊天可以同时供多个项目进行对接")
@RequestMapping("/chat/project")
public class ChatProjectController extends BaseController
{
@Autowired
private IChatProjectService chatProjectService;
@Operation(summary = "不分页查询项目列表")
@PreAuthorize("@ss.hasPermi('chat:project:list')")
@GetMapping
public TableDataInfo listAll()
{
List<ChatProject> list = chatProjectService.selectChatProjectList(null);
return getDataTable(list);
}
@Operation(summary = "分页查询项目列表")
@PreAuthorize("@ss.hasPermi('chat:project:list')")
@GetMapping("/list")
public TableDataInfo list(ChatProject chatProject)
{
startPage();
List<ChatProject> list = chatProjectService.selectChatProjectList(chatProject);
return getDataTable(list);
}
@Operation(summary = "导出项目配置列表")
@PreAuthorize("@ss.hasPermi('chat:project:export')")
@Log(title = "项目配置", businessType = BusinessType.EXPORT)
@PostMapping("/export")
public void export(HttpServletResponse response, ChatProject chatProject)
{
List<ChatProject> list = chatProjectService.selectChatProjectList(chatProject);
ExcelUtil<ChatProject> util = new ExcelUtil<ChatProject>(ChatProject.class);
util.exportExcel(response, list, "项目配置数据");
}
@Operation(summary = "获取一个项目的详细信息")
@PreAuthorize("@ss.hasPermi('chat:project:query')")
@GetMapping(value = "/{projectId}")
public AjaxResult getInfo(@PathVariable("projectId") Long projectId)
{
return success(chatProjectService.selectChatProjectByProjectId(projectId));
}
@Operation(summary = "新增项目配置")
@PreAuthorize("@ss.hasPermi('chat:project:add')")
@Log(title = "项目配置", businessType = BusinessType.INSERT)
@PostMapping
public AjaxResult add(@RequestBody ChatProject chatProject)
{
return toAjax(chatProjectService.insertChatProject(chatProject));
}
@Operation(summary = "修改项目")
@PreAuthorize("@ss.hasPermi('chat:project:edit')")
@Log(title = "项目配置", businessType = BusinessType.UPDATE)
@PutMapping
public AjaxResult edit(@RequestBody ChatProject chatProject)
{
return toAjax(chatProjectService.updateChatProject(chatProject));
}
@Operation(summary = "删除项目")
@PreAuthorize("@ss.hasPermi('chat:project:remove')")
@Log(title = "项目配置", businessType = BusinessType.DELETE)
@DeleteMapping("/{projectIds}")
public AjaxResult remove(@PathVariable Long[] projectIds)
{
return toAjax(chatProjectService.deleteChatProjectByProjectIds(projectIds));
}
}IChatProjectService:
/**
* 项目配置Service接口
*
* @author lixianfeng
* @date 2024-06-27
*/
public interface IChatProjectService
{
/**
* 查询项目配置
*
* @param projectId 项目配置主键
* @return 项目配置
*/
public ChatProject selectChatProjectByProjectId(Long projectId);
/**
* 查询项目配置列表
*
* @param chatProject 项目配置
* @return 项目配置集合
*/
public List<ChatProject> selectChatProjectList(ChatProject chatProject);
/**
* 新增项目配置
*
* @param chatProject 项目配置
* @return 结果
*/
public int insertChatProject(ChatProject chatProject);
/**
* 修改项目配置
*
* @param chatProject 项目配置
* @return 结果
*/
public int updateChatProject(ChatProject chatProject);
/**
* 批量删除项目配置
*
* @param projectIds 需要删除的项目配置主键集合
* @return 结果
*/
public int deleteChatProjectByProjectIds(Long[] projectIds);
/**
* 删除项目配置信息
*
* @param projectId 项目配置主键
* @return 结果
*/
public int deleteChatProjectByProjectId(Long projectId);
}ChatProjectServiceImpl:
/**
* 项目配置Service业务层处理
*
* @author lixianfeng
* @date 2024-06-27
*/
@Service
public class ChatProjectServiceImpl implements IChatProjectService
{
@Autowired
private ChatProjectMapper chatProjectMapper;
/**
* 查询项目配置
*
* @param projectId 项目配置主键
* @return 项目配置
*/
@Override
public ChatProject selectChatProjectByProjectId(Long projectId)
{
return chatProjectMapper.selectChatProjectByProjectId(projectId);
}
/**
* 查询项目配置列表
*
* @param chatProject 项目配置
* @return 项目配置
*/
@Override
public List<ChatProject> selectChatProjectList(ChatProject chatProject)
{
return chatProjectMapper.selectChatProjectList(chatProject);
}
/**
* 新增项目配置
*
* @param chatProject 项目配置
* @return 结果
*/
@Override
public int insertChatProject(ChatProject chatProject)
{
chatProject.setCreateTime(DateUtils.getNowDate());
return chatProjectMapper.insertChatProject(chatProject);
}
/**
* 修改项目配置
*
* @param chatProject 项目配置
* @return 结果
*/
@Override
public int updateChatProject(ChatProject chatProject)
{
chatProject.setUpdateTime(DateUtils.getNowDate());
return chatProjectMapper.updateChatProject(chatProject);
}
/**
* 批量删除项目配置
*
* @param projectIds 需要删除的项目配置主键
* @return 结果
*/
@Override
public int deleteChatProjectByProjectIds(Long[] projectIds)
{
return chatProjectMapper.deleteChatProjectByProjectIds(projectIds);
}
/**
* 删除项目配置信息
*
* @param projectId 项目配置主键
* @return 结果
*/
@Override
public int deleteChatProjectByProjectId(Long projectId)
{
return chatProjectMapper.deleteChatProjectByProjectId(projectId);
}
}ChatProjectMapper
/**
* 项目配置Mapper接口
*
* @author lixianfeng
* @date 2024-06-27
*/
public interface ChatProjectMapper
{
/**
* 查询项目配置
*
* @param projectId 项目配置主键
* @return 项目配置
*/
public ChatProject selectChatProjectByProjectId(Long projectId);
/**
* 查询项目配置列表
*
* @param chatProject 项目配置
* @return 项目配置集合
*/
public List<ChatProject> selectChatProjectList(ChatProject chatProject);
/**
* 新增项目配置
*
* @param chatProject 项目配置
* @return 结果
*/
public int insertChatProject(ChatProject chatProject);
/**
* 修改项目配置
*
* @param chatProject 项目配置
* @return 结果
*/
public int updateChatProject(ChatProject chatProject);
/**
* 删除项目配置
*
* @param projectId 项目配置主键
* @return 结果
*/
public int deleteChatProjectByProjectId(Long projectId);
/**
* 批量删除项目配置
*
* @param projectIds 需要删除的数据主键集合
* @return 结果
*/
public int deleteChatProjectByProjectIds(Long[] projectIds);
}ChatProjectMapper.xml
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.chat.mapper.ChatProjectMapper">
<resultMap type="ChatProject" id="ChatProjectResult">
<result property="projectId" column="project_id" />
<result property="projectName" column="project_name" />
<result property="type" column="type" />
<result property="model" column="model" />
<result property="createBy" column="create_by" />
<result property="createTime" column="create_time" />
<result property="updateBy" column="update_by" />
<result property="updateTime" column="update_time" />
<result property="remark" column="remark" />
</resultMap>
<sql id="selectChatProjectVo">
select project_id, project_name, type, model, create_by, create_time, update_by, update_time, remark from chat_project
</sql>
<select id="selectChatProjectList" parameterType="ChatProject" resultMap="ChatProjectResult">
<include refid="selectChatProjectVo"/>
<where>
<if test="projectName != null and projectName != ''"> and project_name like concat('%', #{projectName}, '%')</if>
<if test="type != null and type != ''"> and type = #{type}</if>
<if test="model != null and model != ''"> and model = #{model}</if>
</where>
</select>
<select id="selectChatProjectByProjectId" parameterType="Long" resultMap="ChatProjectResult">
<include refid="selectChatProjectVo"/>
where project_id = #{projectId}
</select>
<insert id="insertChatProject" parameterType="ChatProject" useGeneratedKeys="true" keyProperty="projectId">
insert into chat_project
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="projectName != null">project_name,</if>
<if test="type != null">type,</if>
<if test="model != null">model,</if>
<if test="createBy != null">create_by,</if>
<if test="createTime != null">create_time,</if>
<if test="updateBy != null">update_by,</if>
<if test="updateTime != null">update_time,</if>
<if test="remark != null">remark,</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="projectName != null">#{projectName},</if>
<if test="type != null">#{type},</if>
<if test="model != null">#{model},</if>
<if test="createBy != null">#{createBy},</if>
<if test="createTime != null">#{createTime},</if>
<if test="updateBy != null">#{updateBy},</if>
<if test="updateTime != null">#{updateTime},</if>
<if test="remark != null">#{remark},</if>
</trim>
</insert>
<update id="updateChatProject" parameterType="ChatProject">
update chat_project
<trim prefix="SET" suffixOverrides=",">
<if test="projectName != null">project_name = #{projectName},</if>
<if test="type != null">type = #{type},</if>
<if test="model != null">model = #{model},</if>
<if test="createBy != null">create_by = #{createBy},</if>
<if test="createTime != null">create_time = #{createTime},</if>
<if test="updateBy != null">update_by = #{updateBy},</if>
<if test="updateTime != null">update_time = #{updateTime},</if>
<if test="remark != null">remark = #{remark},</if>
</trim>
where project_id = #{projectId}
</update>
<delete id="deleteChatProjectByProjectId" parameterType="Long">
delete from chat_project where project_id = #{projectId}
</delete>
<delete id="deleteChatProjectByProjectIds" parameterType="String">
delete from chat_project where project_id in
<foreach item="projectId" collection="array" open="(" separator="," close=")">
#{projectId}
</foreach>
</delete>
</mapper>6.5. 知识库管理
ChatKnowledgeController:
/**
* 知识库管理Controller
*
* @author lixianfeng
* @date 2024-06-27
*/
@RestController
@Tag(name = "知识库后台管理")
@RequestMapping("/chat/knowledge")
public class ChatKnowledgeController extends BaseController
{
@Autowired
private IChatKnowledgeService chatKnowledgeService;
@Autowired
private AiService aiService;
@Operation(summary = "不分页查询知识库管理列表")
@PreAuthorize("@ss.hasPermi('chat:knowledge:list')")
@GetMapping
public TableDataInfo getByProjectId(ChatKnowledge chatKnowledge){
List<ChatKnowledge> list = chatKnowledgeService.selectChatKnowledgeList(chatKnowledge);
return getDataTable(list);
}
@Operation(summary = "分页查询知识库管理列表")
@PreAuthorize("@ss.hasPermi('chat:knowledge:list')")
@GetMapping("/list")
public TableDataInfo list(ChatKnowledge chatKnowledge)
{
startPage();
List<ChatKnowledge> list = chatKnowledgeService.selectChatKnowledgeList(chatKnowledge);
return getDataTable(list);
}
@Operation(summary = "知识库上传")
@PreAuthorize("@ss.hasPermi('chat:knowledge:add')")
@PostMapping("upload")
public AjaxResult upload(ChatKnowledge chatKnowledge, MultipartFile file){
chatKnowledge.setUserId(getUserId());
chatKnowledge.setCreateBy(getUsername());
return success(aiService.upload(chatKnowledge, file));
}
@Operation(summary = "知识库删除")
@PreAuthorize("@ss.hasPermi('chat:knowledge:remove')")
@DeleteMapping("remove")
public AjaxResult removeFile(@RequestParam Long projectId, @RequestParam Long knowledgeId){
aiService.remove(projectId, knowledgeId);
return success("删除成功");
}
@Operation(summary = "导出知识库管理列表")
@PreAuthorize("@ss.hasPermi('chat:knowledge:export')")
@Log(title = "知识库管理", businessType = BusinessType.EXPORT)
@PostMapping("/export")
public void export(HttpServletResponse response, ChatKnowledge chatKnowledge)
{
List<ChatKnowledge> list = chatKnowledgeService.selectChatKnowledgeList(chatKnowledge);
ExcelUtil<ChatKnowledge> util = new ExcelUtil<ChatKnowledge>(ChatKnowledge.class);
util.exportExcel(response, list, "知识库管理数据");
}
@Operation(summary = "获取知识库管理详细信息")
@PreAuthorize("@ss.hasPermi('chat:knowledge:query')")
@GetMapping(value = "/{knowledgeId}")
public AjaxResult getInfo(@PathVariable("knowledgeId") Long knowledgeId)
{
return success(chatKnowledgeService.selectChatKnowledgeByKnowledgeId(knowledgeId));
}
@Operation(summary = "新增知识库管理")
@PreAuthorize("@ss.hasPermi('chat:knowledge:add')")
@Log(title = "知识库管理", businessType = BusinessType.INSERT)
@PostMapping
public AjaxResult add(@RequestBody ChatKnowledge chatKnowledge)
{
return toAjax(chatKnowledgeService.insertChatKnowledge(chatKnowledge));
}
@Operation(summary = "修改知识库管理")
@PreAuthorize("@ss.hasPermi('chat:knowledge:edit')")
@Log(title = "知识库管理", businessType = BusinessType.UPDATE)
@PutMapping
public AjaxResult edit(@RequestBody ChatKnowledge chatKnowledge)
{
return toAjax(chatKnowledgeService.updateChatKnowledge(chatKnowledge));
}
@Operation(summary = "删除知识库管理")
@PreAuthorize("@ss.hasPermi('chat:knowledge:remove')")
@Log(title = "知识库管理", businessType = BusinessType.DELETE)
@DeleteMapping
public AjaxResult remove(@RequestBody ChatKnowledge knowledge){
return toAjax(this.aiService.remove(knowledge.getProjectId(), knowledge.getKnowledgeId()));
}
}AIService:
@Component
public class AiService implements ApplicationContextAware {
// 策略模式 的 bean容器
private final Map<String, AiOperator> MAP = new ConcurrentHashMap<>();
@Autowired
private IChatProjectService projectService;
@Autowired
private IChatKnowledgeService knowledgeService;
@Autowired
private MongoTemplate mongoTemplate;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
Map<String, Object> beanMap = applicationContext.getBeansWithAnnotation(BeanType.class);
if (CollectionUtils.isEmpty(beanMap)) {
return;
}
// 遍历放入Map集合
beanMap.values().forEach(bean -> {
BeanType beanType = bean.getClass().getAnnotation(BeanType.class);
String model = beanType.value().getType();
MAP.put(model, (AiOperator) bean);
});
}
private AiOperator getAiOperator(String type) {
return MAP.get(type);
}
@Transactional
public Long upload(ChatKnowledge chatKnowledge, MultipartFile file) {
// 根据项目id查询项目,获取类型 及 具体模型
ChatProject chatProject = this.projectService.selectChatProjectByProjectId(chatKnowledge.getProjectId());
// 获取文件名 及 内容
String filename = file.getOriginalFilename();
String content = FileUtil.getContentFromText(file);
// 把知识库记录保存到mysql
chatKnowledge.setProjectId(chatProject.getProjectId());
chatKnowledge.setFileName(filename);
chatKnowledge.setContent(content);
this.knowledgeService.insertChatKnowledge(chatKnowledge);
Long knowledgeId = chatKnowledge.getKnowledgeId();
// 上传到redis向量数据库
this.getAiOperator(chatProject.getType()).upload(chatProject.getProjectId(), knowledgeId, content);
return knowledgeId;
}
@Transactional
public Boolean remove(Long projectId, Long knowledgeId) {
// 根据项目id查询项目,获取类型 及 具体模型
ChatProject project = this.projectService.selectChatProjectByProjectId(projectId);
// 删除知识库记录
this.knowledgeService.deleteChatKnowledgeByKnowledgeId(knowledgeId);
// 删除redis向量数据库中对应的文档
return this.getAiOperator(project.getType()).remove(knowledgeId.toString());
}
}IChatKnowledgeService:
/**
* 知识库管理Service接口
*
* @author lixianfeng
* @date 2024-06-27
*/
public interface IChatKnowledgeService
{
/**
* 查询知识库管理
*
* @param knowledgeId 知识库管理主键
* @return 知识库管理
*/
public ChatKnowledge selectChatKnowledgeByKnowledgeId(Long knowledgeId);
/**
* 查询知识库管理列表
*
* @param chatKnowledge 知识库管理
* @return 知识库管理集合
*/
public List<ChatKnowledge> selectChatKnowledgeList(ChatKnowledge chatKnowledge);
/**
* 新增知识库管理
*
* @param chatKnowledge 知识库管理
* @return 结果
*/
public int insertChatKnowledge(ChatKnowledge chatKnowledge);
/**
* 修改知识库管理
*
* @param chatKnowledge 知识库管理
* @return 结果
*/
public int updateChatKnowledge(ChatKnowledge chatKnowledge);
/**
* 批量删除知识库管理
*
* @param knowledgeIds 需要删除的知识库管理主键集合
* @return 结果
*/
public int deleteChatKnowledgeByKnowledgeIds(Long[] knowledgeIds);
/**
* 删除知识库管理信息
*
* @param knowledgeId 知识库管理主键
* @return 结果
*/
public int deleteChatKnowledgeByKnowledgeId(Long knowledgeId);
}ChatKnowledgeServiceImpl:
/**
* 知识库管理Service业务层处理
*
* @author lixianfeng
* @date 2024-06-27
*/
@Service
public class ChatKnowledgeServiceImpl implements IChatKnowledgeService
{
@Autowired
private ChatKnowledgeMapper chatKnowledgeMapper;
/**
* 查询知识库管理
*
* @param knowledgeId 知识库管理主键
* @return 知识库管理
*/
@Override
public ChatKnowledge selectChatKnowledgeByKnowledgeId(Long knowledgeId)
{
return chatKnowledgeMapper.selectChatKnowledgeByKnowledgeId(knowledgeId);
}
/**
* 查询知识库管理列表
*
* @param chatKnowledge 知识库管理
* @return 知识库管理
*/
@Override
public List<ChatKnowledge> selectChatKnowledgeList(ChatKnowledge chatKnowledge)
{
return chatKnowledgeMapper.selectChatKnowledgeList(chatKnowledge);
}
/**
* 新增知识库管理
*
* @param chatKnowledge 知识库管理
* @return 结果
*/
@Override
public int insertChatKnowledge(ChatKnowledge chatKnowledge)
{
chatKnowledge.setCreateTime(DateUtils.getNowDate());
return chatKnowledgeMapper.insertChatKnowledge(chatKnowledge);
}
/**
* 修改知识库管理
*
* @param chatKnowledge 知识库管理
* @return 结果
*/
@Override
public int updateChatKnowledge(ChatKnowledge chatKnowledge)
{
chatKnowledge.setUpdateTime(DateUtils.getNowDate());
return chatKnowledgeMapper.updateChatKnowledge(chatKnowledge);
}
/**
* 批量删除知识库管理
*
* @param knowledgeIds 需要删除的知识库管理主键
* @return 结果
*/
@Override
public int deleteChatKnowledgeByKnowledgeIds(Long[] knowledgeIds)
{
return chatKnowledgeMapper.deleteChatKnowledgeByKnowledgeIds(knowledgeIds);
}
/**
* 删除知识库管理信息
*
* @param knowledgeId 知识库管理主键
* @return 结果
*/
@Override
public int deleteChatKnowledgeByKnowledgeId(Long knowledgeId)
{
return chatKnowledgeMapper.deleteChatKnowledgeByKnowledgeId(knowledgeId);
}
}ChatKnowledgeMapper:
/**
* 知识库管理Mapper接口
*
* @author lixianfeng
* @date 2024-06-27
*/
public interface ChatKnowledgeMapper
{
/**
* 查询知识库管理
*
* @param knowledgeId 知识库管理主键
* @return 知识库管理
*/
public ChatKnowledge selectChatKnowledgeByKnowledgeId(Long knowledgeId);
/**
* 查询知识库管理列表
*
* @param chatKnowledge 知识库管理
* @return 知识库管理集合
*/
public List<ChatKnowledge> selectChatKnowledgeList(ChatKnowledge chatKnowledge);
/**
* 新增知识库管理
*
* @param chatKnowledge 知识库管理
* @return 结果
*/
public int insertChatKnowledge(ChatKnowledge chatKnowledge);
/**
* 修改知识库管理
*
* @param chatKnowledge 知识库管理
* @return 结果
*/
public int updateChatKnowledge(ChatKnowledge chatKnowledge);
/**
* 删除知识库管理
*
* @param knowledgeId 知识库管理主键
* @return 结果
*/
public int deleteChatKnowledgeByKnowledgeId(Long knowledgeId);
/**
* 批量删除知识库管理
*
* @param knowledgeIds 需要删除的数据主键集合
* @return 结果
*/
public int deleteChatKnowledgeByKnowledgeIds(Long[] knowledgeIds);
}ChatKnowledgeMapper.xml:
<?xml version="1.0" encoding="UTF-8" ?>
<!DOCTYPE mapper
PUBLIC "-//mybatis.org//DTD Mapper 3.0//EN"
"http://mybatis.org/dtd/mybatis-3-mapper.dtd">
<mapper namespace="com.atguigu.chat.mapper.ChatKnowledgeMapper">
<resultMap type="ChatKnowledge" id="ChatKnowledgeResult">
<result property="knowledgeId" column="knowledge_id" />
<result property="userId" column="user_id" />
<result property="projectId" column="project_id" />
<result property="fileName" column="file_name" />
<result property="content" column="content" />
<result property="createBy" column="create_by" />
<result property="createTime" column="create_time" />
<result property="updateBy" column="update_by" />
<result property="updateTime" column="update_time" />
<result property="remark" column="remark" />
</resultMap>
<sql id="selectChatKnowledgeVo">
select knowledge_id, user_id, project_id, file_name, content, create_by, create_time, update_by, update_time, remark from chat_knowledge
</sql>
<select id="selectChatKnowledgeList" parameterType="ChatKnowledge" resultMap="ChatKnowledgeResult">
<include refid="selectChatKnowledgeVo"/>
<where>
<if test="userId != null "> and user_id = #{userId}</if>
<if test="projectId != null "> and project_id = #{projectId}</if>
<if test="fileName != null and fileName != ''"> and file_name like concat('%', #{fileName}, '%')</if>
<if test="content != null and content != ''"> and content = #{content}</if>
</where>
</select>
<select id="selectChatKnowledgeByKnowledgeId" parameterType="Long" resultMap="ChatKnowledgeResult">
<include refid="selectChatKnowledgeVo"/>
where knowledge_id = #{knowledgeId}
</select>
<insert id="insertChatKnowledge" parameterType="ChatKnowledge" useGeneratedKeys="true" keyProperty="knowledgeId">
insert into chat_knowledge
<trim prefix="(" suffix=")" suffixOverrides=",">
<if test="userId != null">user_id,</if>
<if test="projectId != null">project_id,</if>
<if test="fileName != null and fileName != ''">file_name,</if>
<if test="content != null">content,</if>
<if test="createBy != null">create_by,</if>
<if test="createTime != null">create_time,</if>
<if test="updateBy != null">update_by,</if>
<if test="updateTime != null">update_time,</if>
<if test="remark != null">remark,</if>
</trim>
<trim prefix="values (" suffix=")" suffixOverrides=",">
<if test="userId != null">#{userId},</if>
<if test="projectId != null">#{projectId},</if>
<if test="fileName != null and fileName != ''">#{fileName},</if>
<if test="content != null">#{content},</if>
<if test="createBy != null">#{createBy},</if>
<if test="createTime != null">#{createTime},</if>
<if test="updateBy != null">#{updateBy},</if>
<if test="updateTime != null">#{updateTime},</if>
<if test="remark != null">#{remark},</if>
</trim>
</insert>
<update id="updateChatKnowledge" parameterType="ChatKnowledge">
update chat_knowledge
<trim prefix="SET" suffixOverrides=",">
<if test="userId != null">user_id = #{userId},</if>
<if test="projectId != null">project_id = #{projectId},</if>
<if test="fileName != null and fileName != ''">file_name = #{fileName},</if>
<if test="content != null">content = #{content},</if>
<if test="createBy != null">create_by = #{createBy},</if>
<if test="createTime != null">create_time = #{createTime},</if>
<if test="updateBy != null">update_by = #{updateBy},</if>
<if test="updateTime != null">update_time = #{updateTime},</if>
<if test="remark != null">remark = #{remark},</if>
</trim>
where knowledge_id = #{knowledgeId}
</update>
<delete id="deleteChatKnowledgeByKnowledgeId" parameterType="Long">
delete from chat_knowledge where knowledge_id = #{knowledgeId}
</delete>
<delete id="deleteChatKnowledgeByKnowledgeIds" parameterType="String">
delete from chat_knowledge where knowledge_id in
<foreach item="knowledgeId" collection="array" open="(" separator="," close=")">
#{knowledgeId}
</foreach>
</delete>
</mapper>AiOperator:
public interface AiOperator {
/**
* 上传本地知识库
*
* @param projectId
* @param knowledgeId
* @param content
* @return
*/
Boolean upload(Long projectId, Long knowledgeId, String content);
/**
* 移除本地知识库
* @param docId
* @return
*/
Boolean remove(String docId);
}OllamaOperator:
@BeanType(AiTypeEnum.OLLAMA)
public class OllamaOperator implements AiOperator {
@Autowired
private OllamaChatModel ollamaChatModel;
@Resource
private RedisVectorStore ollamaRedisVectorStore;
@Autowired
private MongoTemplate mongoTemplate;
@Override
public Boolean upload(Long projectId, Long knowledgeId, String content) {
Document document = new Document(knowledgeId.toString(), content, Map.of("projectId", projectId));
this.ollamaRedisVectorStore.add(List.of(document));
return true;
}
@Override
public Boolean remove(String docId) {
return this.ollamaRedisVectorStore.delete(List.of(docId)).get();
}
}6.6. 会话管理及聊天
具体内容:
@RestController
@Tag(name = "AI大模型交互")
@RequestMapping("ai")
public class ChatController {
@Autowired
private AiService aiService;
@Operation(summary = "文本问答")
@PostMapping(value = "chat-stream", produces = "text/plain;charset=UTF-8")
public Flux<String> chatStream(@RequestBody @Valid QueryVo queryVo) {
return aiService.chatStream(queryVo);
}
@Operation(summary = "创建新的会话")
@PostMapping("create-chat")
public String createChat(@Valid ChatVo chatVo){
return this.aiService.createChat(chatVo);
}
@Operation(summary = "修改会话标题")
@PostMapping("update-chat")
public void updateChat(ChatVo chatVo){
this.aiService.updateChat(chatVo);
}
@Operation(summary = "查询会话列表")
@GetMapping("list-chat")
public List<Chat> listChat(Long projectId, Long userId){
return this.aiService.listChat(projectId, userId);
}
@Operation(summary = "删除一个会话")
@GetMapping("delete-chat")
public void deleteChat(Long projectId, Long chatId){
this.aiService.deleteChat(projectId, chatId);
}
@Operation(summary = "查询一个会话中的问答消息")
@GetMapping("list-msg")
public List<Message> listMsg(Long chatId){
return this.aiService.listMsg(chatId);
}
@Operation(summary = "如果需要保存AI回答的结果,调用此接口")
@PostMapping("save-msg")
public void saveMsg(@Valid @RequestBody MessageVo messageVo){
this.aiService.saveMsg(messageVo);
}
}AiService:
@Component
public class AiService implements ApplicationContextAware {
// 策略模式 的 bean容器
private final Map<String, AiOperator> MAP = new ConcurrentHashMap<>();
@Autowired
private IChatProjectService projectService;
@Autowired
private MongoTemplate mongoTemplate;
@Override
public void setApplicationContext(ApplicationContext applicationContext) throws BeansException {
Map<String, Object> beanMap = applicationContext.getBeansWithAnnotation(BeanType.class);
if (CollectionUtils.isEmpty(beanMap)) {
return;
}
// 遍历放入Map集合
beanMap.values().forEach(bean -> {
BeanType beanType = bean.getClass().getAnnotation(BeanType.class);
String model = beanType.value().getType();
MAP.put(model, (AiOperator) bean);
});
}
private AiOperator getAiService(String type) {
return MAP.get(type);
}
public Flux<String> chatStream(QueryVo queryVo) {
// 根据项目id查询项目,获取类型 及 具体模型
ChatProject chatProject = this.projectService.selectChatProjectByProjectId(queryVo.getProjectId());
return this.getAiOperator(chatProject.getType()).chatStream(chatProject.getModel(), queryVo);
}
public String createChat(ChatVo chatVo) {
Chat chat = new Chat();
BeanUtils.copyProperties(chatVo, chat);
chat.setCreateTime(new Date());
Long chatId = IdUtil.getSnowflake().nextId();
chat.setChatId(chatId);
this.mongoTemplate.insert(chat, MongoUtil.getChatCollection(chatVo.getProjectId()));
return chatId.toString();
}
public List<Chat> listChat(Long projectId, Long userId) {
return this.mongoTemplate.find(
Query.query(Criteria.where("userId").is(userId)).with(Sort.by(Sort.Order.desc("createTime"))),
Chat.class,
MongoUtil.getChatCollection(projectId)
);
}
public void updateChat(ChatVo chatVo) {
if (chatVo == null || chatVo.getProjectId() == null) {
throw new RuntimeException("projectId不能为空");
}
this.mongoTemplate.updateFirst(
Query.query(Criteria.where("_id").is(chatVo.getChatId())),
Update.update("title", chatVo.getTitle()),
MongoUtil.getChatCollection(chatVo.getProjectId())
);
}
public void deleteChat(Long projectId, Long chatId) {
if (projectId == null || chatId == null) {
throw new RuntimeException("projectId或chatId不能为空");
}
this.mongoTemplate.remove(Query.query(Criteria.where("_id").is(chatId)), MongoUtil.getChatCollection(projectId));
}
public List<Message> listMsg(Long chatId) {
if (chatId == null) {
throw new RuntimeException("chatId不能为空");
}
return this.mongoTemplate.find(
Query.query(Criteria.where("chatId").is(chatId)).with(Sort.by(Sort.Order.asc("createTime"))),
Message.class,
MongoUtil.getMessageCollection(chatId)
);
}
public void saveMsg(MessageVo messageVo) {
Message message = new Message();
BeanUtils.copyProperties(messageVo, message);
message.setCreateTime(new Date());
message.setType(1);
message.setId(IdUtil.getSnowflake().nextId());
this.mongoTemplate.insert(message, MongoUtil.getMessageCollection(messageVo.getChatId()));
}
} AiOperator:
public interface AiOperator {
........
/**
* 一次性输出文本问答
* @param queryVo QueryVo
* @return
*/
default String chat(QueryVo queryVo){
throw new UnsupportedOperationException();
}
/**
* 流式输出文本问答
*
* @param model
* @param queryVo QueryVo
* @return
*/
default Flux<String> chatStream(String model, QueryVo queryVo){
throw new UnsupportedOperationException();
}
}OllamaOperator:
@BeanType(AiTypeEnum.OLLAMA)
public class OllamaOperator implements AiOperator {
@Autowired
private OllamaChatModel ollamaChatModel;
@Resource
private RedisVectorStore ollamaRedisVectorStore;
@Autowired
private MongoTemplate mongoTemplate;
@Override
public String chat(QueryVo queryVo) {
return null;
}
@Override
public Flux<String> chatStream(String model, QueryVo queryVo) {
// 把问题记录到mongodb
Long chatId = queryVo.getChatId();
if (chatId != null) {
com.atguigu.ai.pojo.Message msg = new com.atguigu.ai.pojo.Message();
msg.setChatId(queryVo.getChatId());
msg.setType(0);
msg.setContent(queryVo.getMsg());
msg.setCreateTime(new Date());
msg.setId(IdUtil.getSnowflake().nextId());
this.mongoTemplate.insert(msg, MongoUtil.getMessageCollection(queryVo.getChatId()));
}
// 查询本地知识库
List<Document> results = ollamaRedisVectorStore.similaritySearch(SearchRequest
.query(queryVo.getMsg())
.withFilterExpression(
new FilterExpressionBuilder()
.eq("projectId", queryVo.getProjectId()) // 查询当前用户及管理员的本地知识库
.build())
.withTopK(SystemEnum.TOPK)); // 取前10个
// 把本地知识库的内容作为系统提示放入
List<Message> msgList = results.stream().map(result ->
new SystemMessage(result.getContent())).collect(Collectors.toList());
// 中英文切换
msgList.add(new SystemMessage(LanguageEnum.getMsg(queryVo.getLanguage())));
// 加入当前用户的提问
msgList.add(new UserMessage(queryVo.getMsg()));
// 提交到大模型获取最终结果
Flux<ChatResponse> responseFlux = this.ollamaChatModel.stream(new Prompt(msgList, OllamaOptions.create().withModel(model)));
return responseFlux.map(response -> response.getResult() != null
&& response.getResult().getOutput() != null
&& response.getResult().getOutput().getContent() != null
? response.getResult().getOutput().getContent() : "");
}
}
评论