
随着人工智能技术的快速发展,企业和开发者对大模型的需求越来越迫切。然而,如何私有化部署大模型以确保数据安全,同时提高企业运营效率,是一个备受关注的话题。本篇文章将深入探讨大模型私有部署的背景、意义及其具体实施方案。
为什么需要私有大模型?
近年来,大模型在提升生产力和推动创新方面展现出了强大的潜力,但其广泛应用也暴露出一些问题,尤其是数据隐私与安全。例如,三星员工曾因使用公共大模型工具(如ChatGPT)意外泄露公司机密。这一事件凸显了公共大模型在数据处理中的风险。
私有大模型的优势
数据安全:通过将模型部署在企业内部,避免敏感数据暴露于公共网络。
定制化:根据企业需求微调模型,提高模型对行业专属场景的适应能力。
降低运营成本:优化模型训练和推理,减少公共服务的调用费用。
提高效率:为内部员工提供高效工具,促进生产力提升。
私有大模型解决方案:Ollama与LM Studio
为了满足开发者和企业对私有大模型的需求,社区涌现了两款重要工具:Ollama 和 LM Studio。以下是两者的对比:
Ollama 的开源特性使其成为许多企业的首选,本课程重点介绍其使用方法。
Ollama入门指南
什么是Ollama?
Ollama 是一个开源框架,旨在简化大语言模型的本地部署与管理。它支持运行预构建模型(如 Llama 2、Code Llama 等),并可从多种格式(如 GGUF、PyTorch)导入定制模型。官方网址:Ollama

Ollama 的核心特性
快速部署:通过一站式管理工具,优化复杂模型的配置与加载。
资源高效:支持纯 CPU 推理,占用资源少。
多平台兼容:适用于 macOS、Linux 和 Windows。
安装与配置
手动安装
对于 Linux 用户,可以使用以下步骤完成安装:
通过官网下载安装包并解压:
curl -L https://ollama.com/download/ollama-linux-amd64.tgz -o ollama-linux-amd64.tgz sudo tar -C /usr -xzf ollama-linux-amd64.tgz创建服务文件/etc/systemd/system/ollama.service,配置服务自启:
[Unit] Description=Ollama Service After=network-online.target [Service] ExecStart=/usr/bin/ollama serve User=root Group=root Restart=always RestartSec=3 [Install] WantedBy=default.target# 生效服务: sudo systemctl daemon-reload sudo systemctl enable ollama sudo systemctl start ollama
操作成功之后,可以通过查看版本指令来验证是否安装成功
ollama -v
一键安装
若网络环境良好,可以直接执行以下命令:(国内服务器下载需要科学上网,下图中我所用的是境外服务器)
curl -fsSL https://ollama.com/install.sh | sh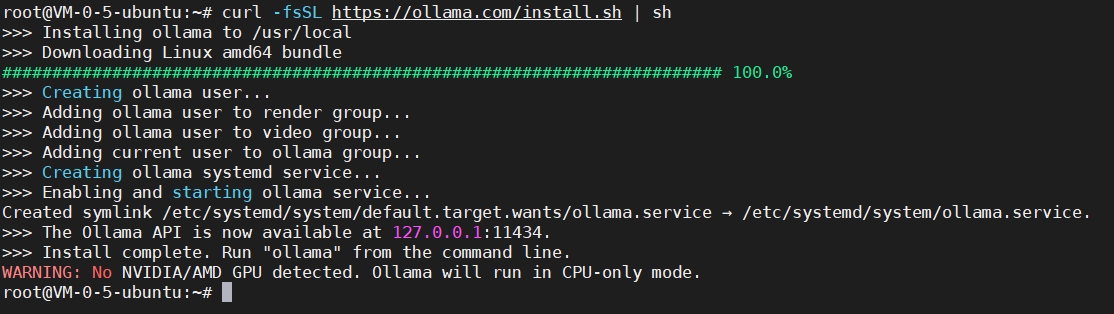
运行示例:通义千问
Ollama 支持快速加载大模型。以运行阿里巴巴的通义千问(Qwen)模型为例:
ollama run qwen2:0.5b
首次运行时会自动下载模型,加载完成后即可通过终端与模型互动。(大模型比较消耗硬盘资源,请确保硬盘容量充足,否则无法运行)
高效使用 Ollama:命令与配置详解
Ollama 提供了丰富的命令行工具,用于调整和优化模型的表现。
常用命令
查看模型信息:
ollama show info设置对话参数:
ollama set parameter top_p 0.8终止会话:
/bye
API 调用
除了 CLI 工具,Ollama 还支持通过 API 调用模型,为开发者提供了灵活的集成方式。
小结
通过 Ollama 和其他私有化大模型工具,企业能够在确保数据安全的前提下,充分利用 AI 的潜力。希望本文为您的学习和实践提供了清晰的路径。如果您有任何问题,欢迎留言交流!
评论