

一、什么是缓存
1.1 缓存的定义
缓存(Cache)是数据交换的缓冲区,作为存储数据的临时场所,具备高读写性能特点。其核心作用在于通过暂存高频访问数据,减少对后端数据源的直接访问压力,从而显著提升系统响应速度。
1.2 缓存的分类
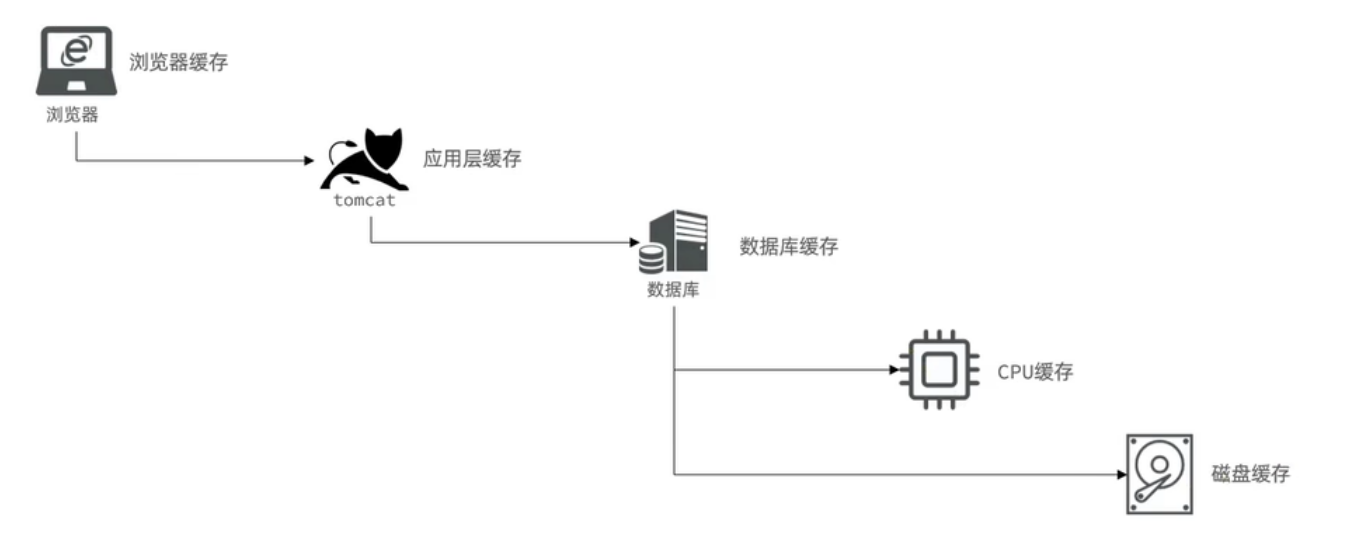
浏览器缓存:存储浏览器访问过的静态资源(如HTML、CSS、JS等),减少重复请求。
应用层缓存:位于应用服务器层(如Tomcat),缓存应用运行过程中产生的中间数据。
数据库缓存:数据库自身提供的缓存机制(如MySQL的InnoDB缓冲池),加速数据查询。
CPU缓存:CPU内部的高速存储单元,用于存储频繁访问的指令和数据,降低CPU访问内存的延迟。
磁盘缓存:操作系统对磁盘操作的缓存,减少磁盘I/O次数,提升数据读写效率。
1.3 缓存的作用与成本
作用
降低后端负载:减少对数据库等后端数据源的直接访问频次。
提高读写效率:通过内存等高速存储介质,降低响应时间。
成本
数据一致性成本:缓存数据与数据源可能存在不一致风险。
代码维护成本:需要额外编写缓存操作逻辑,增加代码复杂度。
运维成本:涉及缓存集群的部署、监控和维护。
二、添加Redis缓存
2.1 缓存作用模型
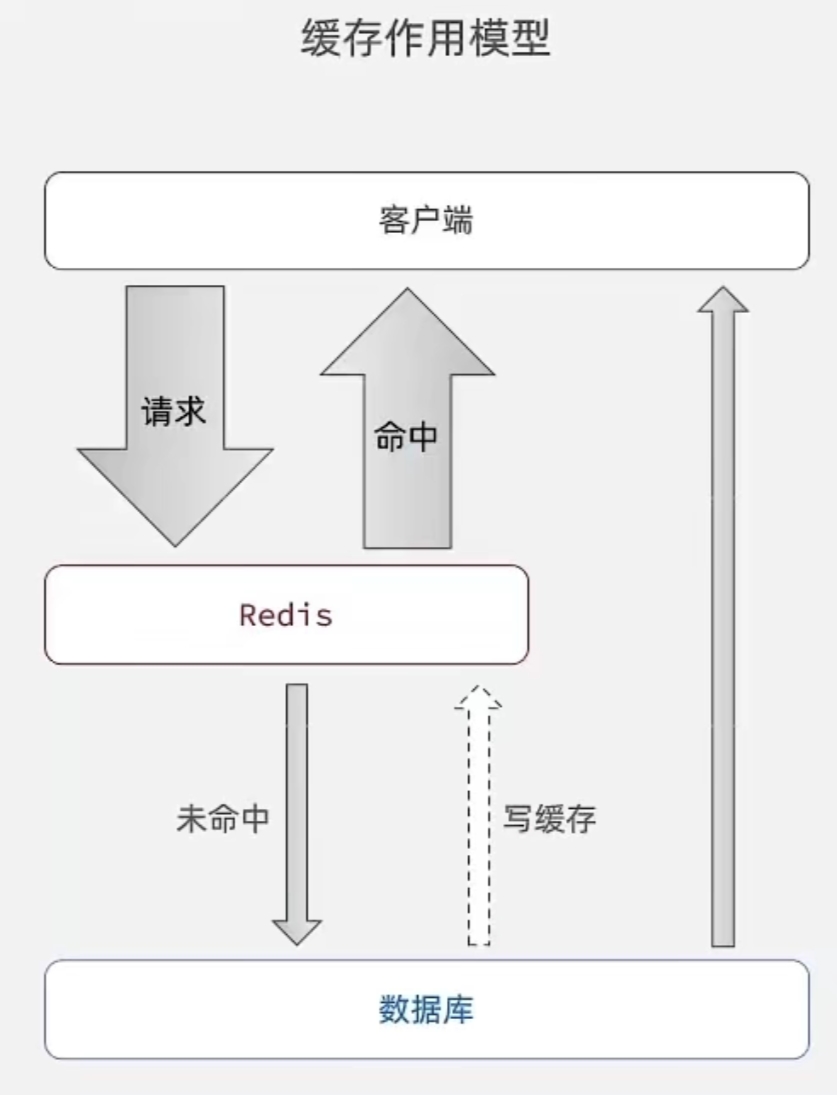
客户端请求数据时,先查询Redis缓存:
若命中缓存,直接返回数据。
若未命中缓存,再查询数据库,并将查询结果写入Redis缓存,供后续请求使用。
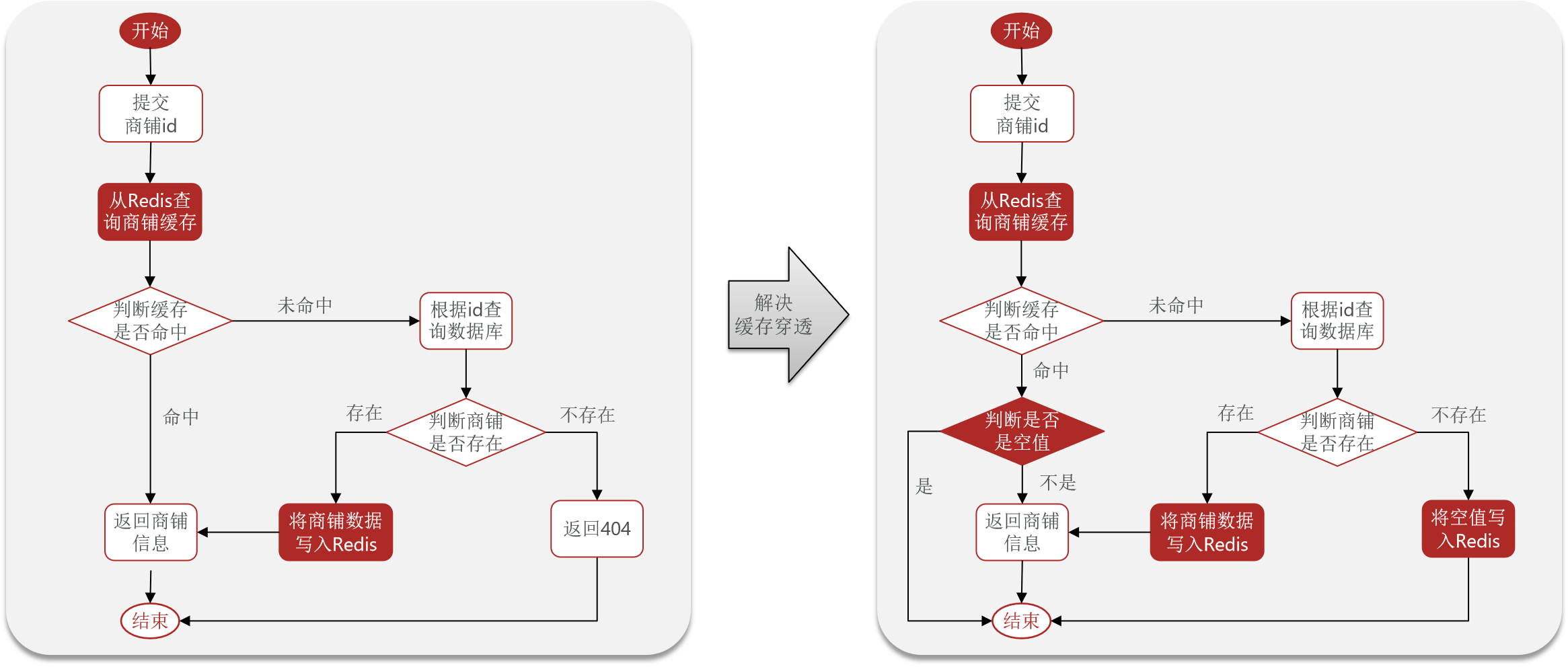
2.2 查询流程示例:根据ID查询商铺
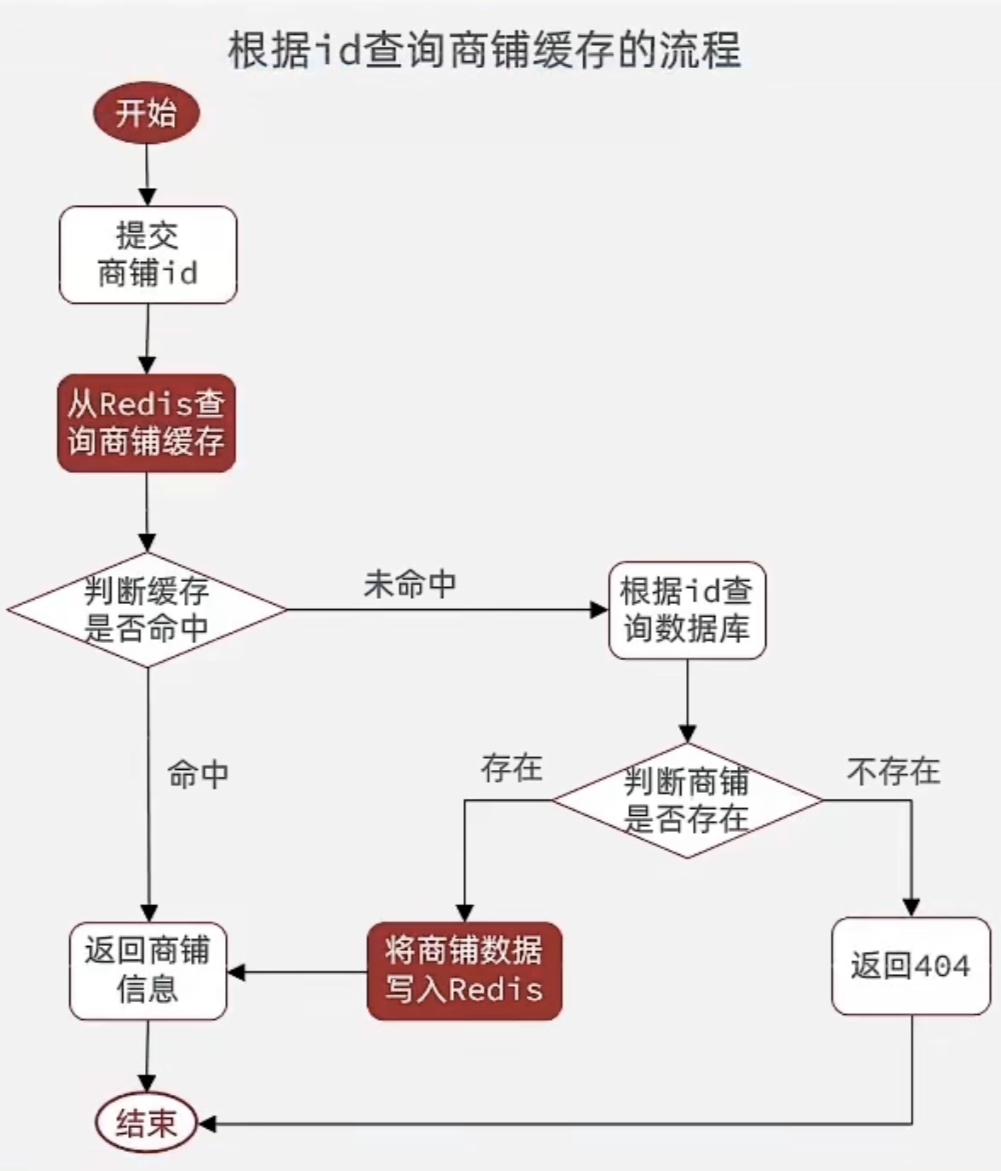
提交商铺ID请求。
判断Redis缓存是否命中:
命中:直接返回商铺信息。
未命中:从数据库查询商铺数据。
若数据库存在该商铺数据,将其写入Redis缓存;若不存在,返回404。
2.3 实战练习:为店铺类型查询添加缓存
需求:修改ShopTypeController的queryTypeList方法,添加Redis缓存。
@GetMapping("list")
public Result queryTypeList() {
// 先从Redis查询缓存
String cacheKey = "shop:types";
String cacheData = stringRedisTemplate.opsForValue().get(cacheKey);
if (StringUtils.isNotBlank(cacheData)) {
return Result.ok(JSONUtil.toList(cacheData, ShopType.class));
}
// 缓存未命中,查询数据库
List<ShopType> typeList = typeService.query().orderByAsc("sort").list();
if (typeList.isEmpty()) {
return Result.ok();
}
// 写入缓存(设置TTL为1小时)
stringRedisTemplate.opsForValue().set(cacheKey, JSONUtil.toJsonStr(typeList), 1, TimeUnit.HOURS);
return Result.ok(typeList);
}三、缓存更新策略
3.1 三种更新策略对比
3.2 主动更新策略详解(Cache Aside Pattern)
操作顺序:先写数据库,再删除缓存(避免脏读)。
原子性保证:
单体系统:将数据库与缓存操作置于同一事务。
分布式系统:使用TCC等分布式事务方案。
线程安全问题:通过互斥锁避免多线程并发更新导致的缓存与数据库不一致。
3.3 最佳实践
低一致性需求:优先使用内存淘汰机制。
高一致性需求:采用“主动更新+超时剔除”组合策略。
四、缓存穿透
4.1 问题定义
指大量请求直接绕过缓存层,直达数据库,导致数据库压力激增的现象(如请求不存在的数据)。
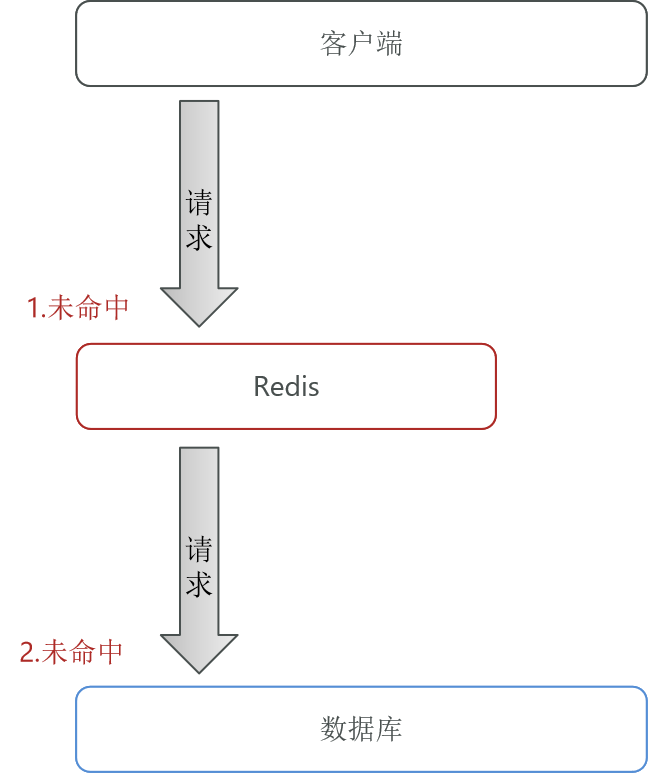
4.2 解决方案
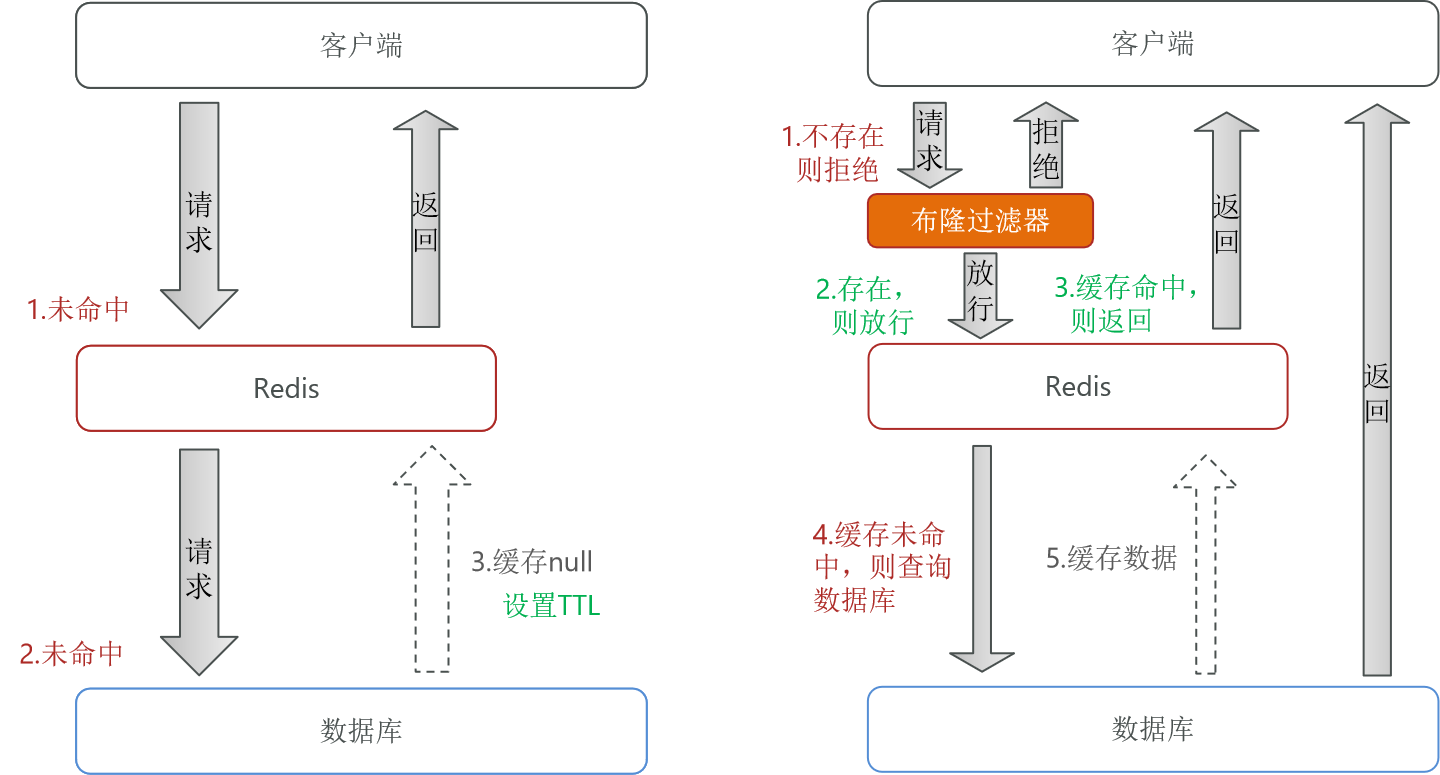
缓存空对象
流程:当数据库查询结果为空时,将null值写入缓存(设置短TTL)。
优点:实现简单,维护方便。
缺点:浪费内存,可能存在短期数据不一致。
布隆过滤器
流程:在请求进入数据库前,通过布隆过滤器过滤无效请求。
优点:内存占用少,无多余Key。
缺点:实现复杂,存在误判可能。
其他辅助措施:增强ID复杂度、校验数据格式、限流等。
4.3 查询流程优化
五、缓存雪崩
5.1 问题定义
指缓存层大面积失效(如服务器宕机、大量 Key 同时过期),导致请求流量集中涌入数据库,造成数据库崩溃的现象。
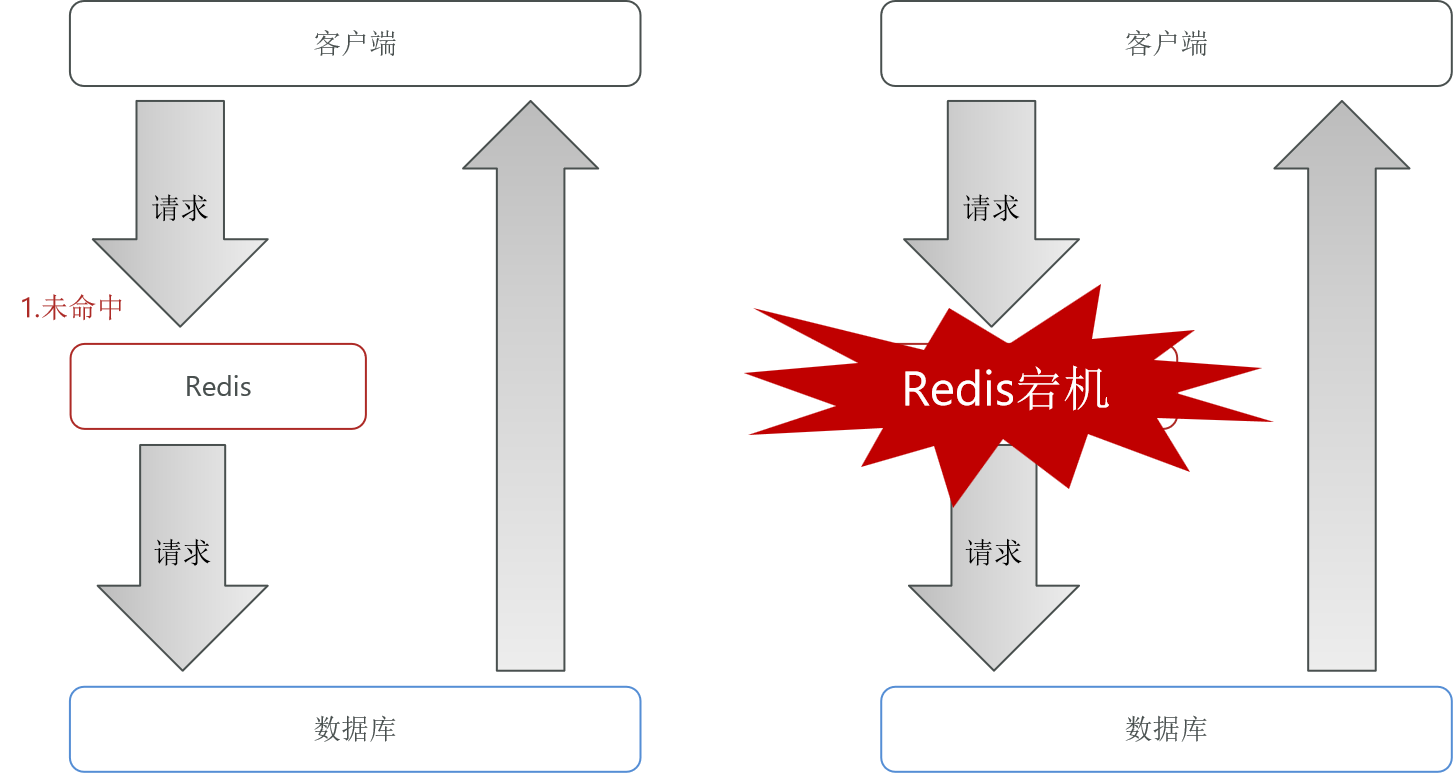
5.2 解决方案
随机TTL:为不同Key设置随机过期时间,避免集中失效。
Redis集群:通过主从复制和分片机制提高服务可用性。
降级限流:对非核心业务进行限流或返回降级数据。
多级缓存:结合本地缓存(如Caffeine)和分布式缓存(Redis),降低对单一缓存的依赖。
六、缓存击穿
6.1 问题定义
缓存击穿问题也叫热点Key问题,就是一个被高并发访问并且缓存重建业务较复杂的key突然失效了,无数的请求访问会在瞬间给数据库带来巨大的冲击。
6.2 解决方案
6.3 实战案例:互斥锁方案
public Shop queryWithLock(Long shopId) {
String cacheKey = "shop:info:" + shopId;
// 1. 查询缓存
String cacheData = stringRedisTemplate.opsForValue().get(cacheKey);
if (StringUtils.isNotBlank(cacheData)) {
return JSONUtil.toBean(cacheData, Shop.class);
}
// 2. 缓存未命中,尝试获取互斥锁
String lockKey = "lock:shop:" + shopId;
Shop shop = null;
try {
boolean isLock = tryLock(lockKey);
if (!isLock) {
// 未获取到锁,休眠重试
Thread.sleep(50);
return queryWithLock(shopId);
}
// 3. 获取锁成功,查询数据库
shop = shopService.getById(shopId);
if (shop == null) {
// 缓存空值解决穿透
stringRedisTemplate.opsForValue().set(cacheKey, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
// 4. 写入缓存
stringRedisTemplate.opsForValue().set(cacheKey, JSONUtil.toJsonStr(shop), CACHE_TTL, TimeUnit.HOURS);
} catch (InterruptedException e) {
throw new RuntimeException(e);
} finally {
// 5. 释放锁
unlock(lockKey);
}
return shop;
}七、缓存工具封装
7.1 需求说明
基于StringRedisTemplate封装通用缓存工具类,实现以下功能:
存储对象并设置TTL:将Java对象序列化为JSON,存入String类型Key,设置过期时间。
存储对象并设置逻辑过期:用于处理缓存击穿场景。
查询缓存并反序列化(空值处理):解决缓存穿透问题。
查询缓存并反序列化(逻辑过期处理):结合逻辑过期方案处理热点Key问题。
7.2 核心代码示例
public class CacheUtils {
private static final String LOGICAL_EXPIRE_KEY = "logical:expire:";
/**
* 存储对象并设置TTL
*/
public static void setWithTTL(String key, Object value, long timeout, TimeUnit unit) {
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(value), timeout, unit);
}
/**
* 存储对象并设置逻辑过期时间
*/
public static void setWithLogicalExpire(String key, Object value, long timeout, TimeUnit unit) {
RedisData redisData = new RedisData();
redisData.setData(value);
redisData.setExpireTime(System.currentTimeMillis() + unit.toMillis(timeout));
stringRedisTemplate.opsForValue().set(key, JSONUtil.toJsonStr(redisData));
}
/**
* 查询缓存并处理空值(穿透解决方案)
*/
public static <R, T> R queryWithPassThrough(String keyPrefix, Long id, Class<T> type,
Function<Long, R> dbFallback, long timeout, TimeUnit unit) {
String key = keyPrefix + id;
String cacheData = stringRedisTemplate.opsForValue().get(key);
if (StringUtils.isNotBlank(cacheData)) {
return JSONUtil.toBean(cacheData, type);
}
if (cacheData != null) { // 处理缓存空值
return null;
}
// 查询数据库
R result = dbFallback.apply(id);
if (result == null) {
stringRedisTemplate.opsForValue().set(key, "", CACHE_NULL_TTL, TimeUnit.MINUTES);
return null;
}
setWithTTL(key, result, timeout, unit);
return result;
}
}八、总结
本文围绕商户查询场景,深入解析了缓存技术的核心概念与实践方案,重点涵盖:
缓存的基础原理与分类。
Redis缓存的集成与查询流程设计。
缓存更新策略的选择与实现。
缓存穿透、雪崩、击穿三大典型问题的成因与解决方案。
通用缓存工具类的封装思路。
通过合理应用缓存技术,可显著提升系统性能与稳定性,但需结合业务场景权衡一致性、性能与维护成本,选择最优方案。
评论